

Fault and Error Tolerance in Neural Networks: A Review
来 源:IEEE Access 2017
原文速递:Fault and Error Tolerance in Neural Networks: A Review
该文对神经网络的容错工作进行了调研,介绍了容错相关名词及定义,并对故障类型、故障模型进行划分。该文重点对神经网络容错工作进行了具体分类:
- 被动容错(Passive fault tolerance)
一个具有被动容错功能的系统不会以任何特殊的方式对内部故障做出反应,而是利用系统结构中的冗余和故障屏蔽有效地屏蔽故障效应。
(a)增加冗余(Explicitly augmenting redundancy)
(b) 调整训练策略(Modifying training/ learning)
在训练过程中加入噪声、扰动或直接引入故障,一些工作在待改进的性能指标中加入惩罚项以间接地引入故障。
(c) 解优化问题(Optimization under constraints)
将训练过程和容错转化为一个非线性优化问题,以找到在容错约束下执行特定任务的神经网络拓扑结构和参数。
- 主动容错(Active fault tolerance)
一个具有主动容错功能的系统能够明确、动态地识别和管理其冗余资源,以补偿故障出现时的影响(通过适应、再训练或自我修复机制)。主动容错需要特殊的检测/定位和监督/控制组件,其设计可能会比较复杂。
1)现有神经网络容错工作大部分针对人工神经网络(ANN)进行设计,对目前的智能应用来说过于简单,且年份久远,许多神经网络的容错工作在上世纪九十年代进行;
2)文中提到的工作基本都为在硬件系统不稳定的设备上进行神经网络容错设计,是在计算或参数存储时造成的错误,不考虑由于传输产生的数据错误;
3)虽然该文涉及的神经网络容错工作部分内容与现在的实际情况有差别,但其对神经网络容错的分类和容错思路仍可以沿用。
NeuroMessenger: Towards Error Tolerant Distributed Machine Learning Over Edge Networks
来 源:IEEE INFOCOM 2022 - IEEE Conference on Computer Communications
原文速递:NeuroMessenger: Towards Error Tolerant Distributed Machine Learning Over Edge Networks
该工作考虑了分布式机器学习(Distributed Machine Learning)中的通信开销问题,提出一种新的容错分布式机器学习范式,用于提升分布式机器学习系统的效率,涉及模型分割式协同推理和联邦学习两个方面。该工作的系统架构如下。
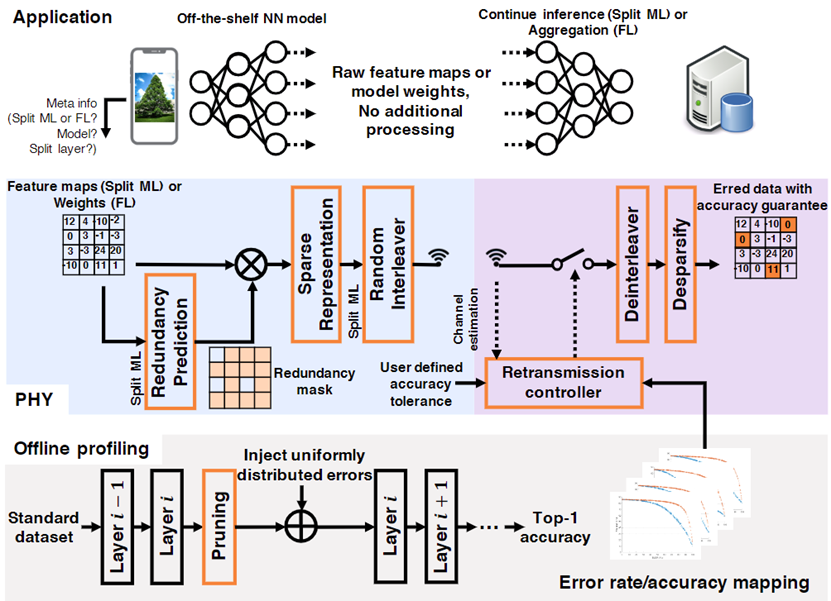
该架构对模型分割或数据聚合时预测准确率与数据错误率的关系进行离线建模,使用重传控制器决定数据重传的次数。在数据容错方面,该框架使用了交织编码和重要性编码两种技术。另外,该工作提出使用特征图剪枝方法减少分布式机器学习的数据传输量。
- 交织编码(Interleaved Coding)
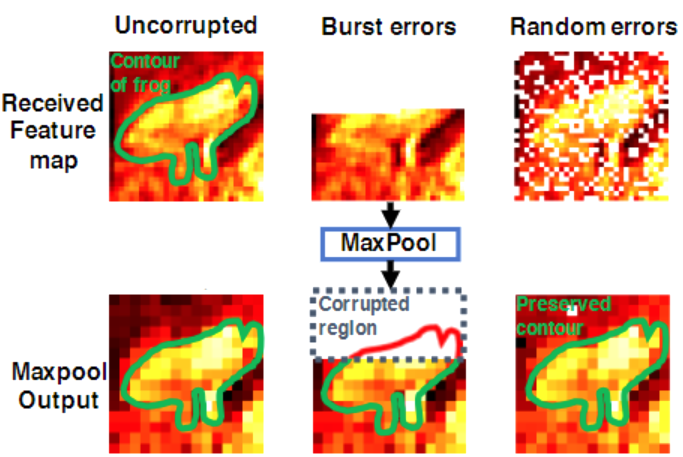
如下图所示,突发错误对预测精度的影响大于随机错误,交织编码通过数据的随机交织将数据传输时产生的突发错误转化为随机错误,降低突发错误对预测精度的影响。
- 重要性编码(Importance-based Coding)
重要性编码根据参数对预测结果的影响对不同参数采取不平等的保护策略,对预测结果影响大的特征被认定为重要特征。
1)该工作考虑了分布式机器学习中数据传输的容错策略,相较传统的神经网络容错工作特点鲜明;
2)该工作需要对模型每层的错误率-精度关系进行离线建模用于评估需要重传的次数,通用性较差。
FT-CNN: Algorithm-Based Fault Tolerance for Convolutional Neural Networks
来 源:IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 32, NO. 7, JULY 2021
原文速递:FT-CNN: Algorithm-Based Fault Tolerance for Convolutional Neural Networks
该工作针对CNN的计算容错问题,提出了多个算法层面的容错方法,用于应对可能发生的软错误(soft errors)。另外,该工作将提出的四种策路集成到一个工作流中,以使用有限的运行开销获得较高的纠改错能力。该工作的容错策略主要通过下图的设计实现,其在原始卷积数据上增加了相应的Checksum部分,用于校验卷积结果是否存在错误,并定位/纠正出现的错误。
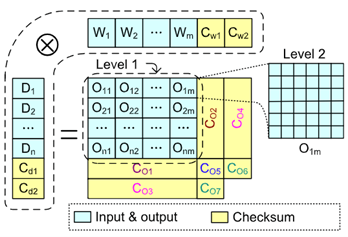
该工作根据Checksum的设计制定了四种容错策略,分别用于定位不同情况的错误类型,并将四种策略嵌入到一个工作流中,在不同情况下进行相应Checksum块的检查,降低多余的判定开销。
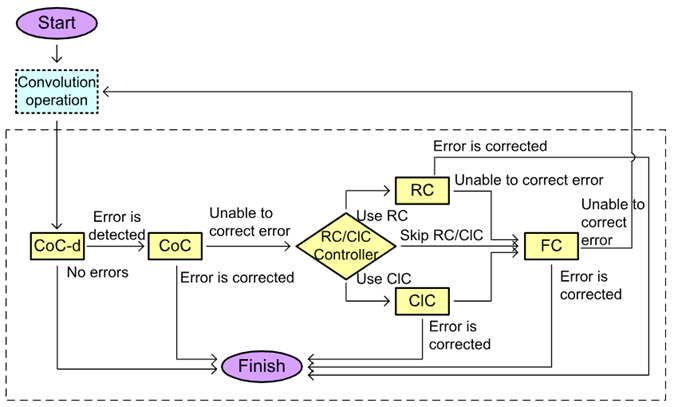
1)该工作针对特征图在传输和计算中出现的错误设计检纠错策略,将通信的数据编码校验融合到传输数据本身;
2)该方式针对每个传输的特征图都需要计算相应的Checksum矩阵,计算量增加,并且增加了传输的冗余量。
Fault-Tolerant Collaborative Inference through the Edge-PRUNE Framework
来 源:DyNN workshop at the 39th International Conference on Machine Learning, Baltimore, Maryland, USA, 2022
原文速递:Fault-Tolerant Collaborative Inference through the Edge-PRUNE Framework
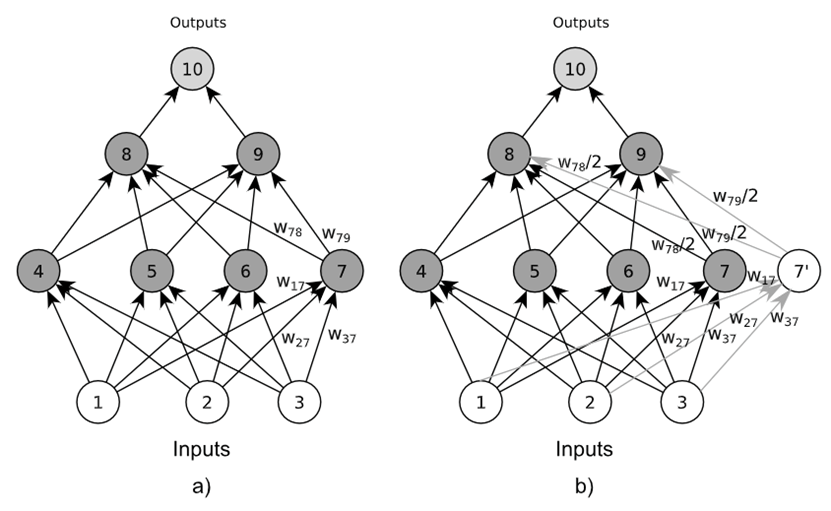
该工作针对多设备协同推理的容错问题提出机器学习框架Edge-PRUNE。该框架能够自动生成端设备和服务器间的协同推理最佳分割点,并根据模型的有向图进行条件计算。该框架实现协同推理容错的方式为将失效设备的计算任务转移到冗余设备上,如下图是一个监控系统的示例。
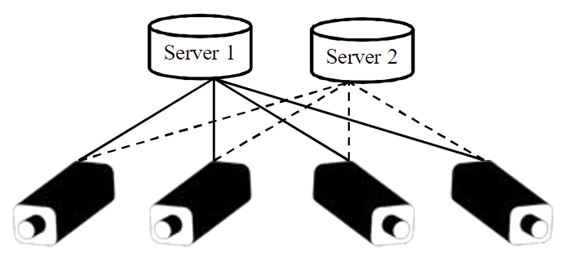
1)该工作将边-端协同推理的模型分割和容错机制设计到了机器学习框架中;
2)Edge-PRUNE对协同推理的容错机制主要通过冗余的设备实现,较为简单且设备的冗余在容错的同时造成了不必要的开销。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.