

来 源:MobiCom ‘22: Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, October 2022
原文速递:Real-time Neural Network Inference on Extremely Weak Devices: Agile Offloading with Explainable AI
Content at a glance
Topic
Deploying NNs on extremely weak devices.
Background
There is a pressing need of enabling real-time neural network (NN) inference on small embedded devices, but deploying NNs and achieving high performance of NN inference on these small devices is challenging due to their extremely weak capabilities. Although NN partitioning and offloading can contribute to such deployment, they are incapable of minimizing the local costs at embedded devices.
Key idea
Enforce feature sparsity by only compressing and transmitting the less important features, the important features are retained at the local device and can be perceived by a lightweight NN with low complexity. Predictions from Local NN and Remote NN are combined at the local device for inference.
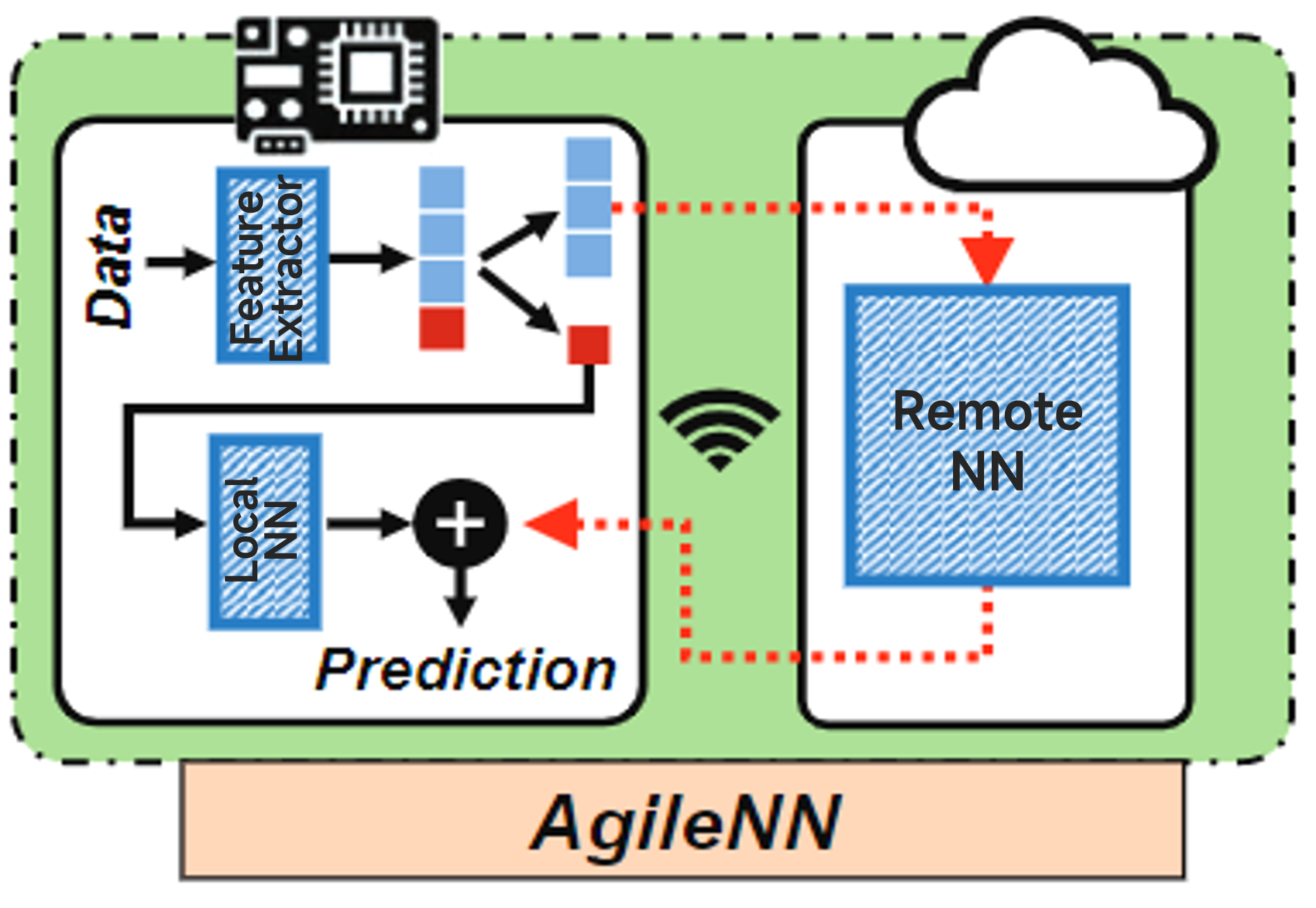
Techniques
Skewness manipulation
The higher the skewness is, the lower resource consumption will be at the local device due to the higher compressibility of less important features being transmitted. AgileNN incorporates both the inference accuracy and current skewness of feature importance into the unified loss function in training. It mandates that the top-k features with highest importance are always in the first k channels of the output feature vector, and ensures that the skewness of feature importance reaches the skewness requirement.
Pre-processing the feature extractor
The feature extractor in AgileNN needs to be deployed at the local device and hence has to be very lightweight, which may not have sufficient representation power to meet the learning objective in the initial phase of training. AgileNN preprocesses the feature extractor and initializes its network weights, prior to the joint training with Local and Remote NNs. In this way, the joint training will not start from scratch but instead from a more established stage with less ambiguity.
Combining local and remote predictions
AgileNN combines the predictions made by the local and remote NNs via weighted summation, and incorporates the summation weight $\alpha$ into the joint training procedure, which avoids some small but important output values in one NN being overwhelmed by large values in another NN.
Comments
- 该文核心观点具有较高的创新性,摆脱传统云端协同推理中的模型分割范式,提供了一种新的协同计算思路——对特征的协同计算,该方案可进一步降低云端协同中数据的传输开销;
- 该工作善于发现问题并借助各种工具解决问题,通过引入XAI这一新领域工具实现对特征的重要程度评估;
- 该文工作量大,联合训练的设计难度大,在文中呈现内容外还存在大量的实验评估和参数优化问题;
- 该文逻辑连贯通顺,无明显漏洞,文章撰写符合系统顶会风格,可看出具有一定的经验。
Presentation Slides
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.