

BRP-NAS: Prediction-based NAS using GCNs
来 源:34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada
与层级时延预测不同,该工作将模型的结构信息也作为时延预测的一个参量,直接预测完整模型的时延。对于图,(是个具有个特征的节点集,是边集),将一个特征描述通过一个邻接矩阵进行编码作为图卷积网络(GCN)的输入。对于一个L层GCN,层间的传播规则为:
其中,和分别是第层的特征图和权重矩阵,是一个非线性激活函数。
该文使用一个4层GCN模型,每层有600个隐藏单元,引入一个全局节点(连接所有节点)汇总所有节点级信息进行图嵌入。
1)考虑整个网络的特性,而非是对单层时延预测值的简单加和,准确度更高;
2)未考虑设备特性,是完全黑盒的预测,模型尺寸可能比较大;
3)泛化能力差,对新模型的支持性差。
Learned TPU Cost Model for XLA Tensor Programs
来 源:33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada
该工作设计了一个基于学习的神经网络性能评估模型,用于预测每个kernel的执行时间,该模型如下图所示。
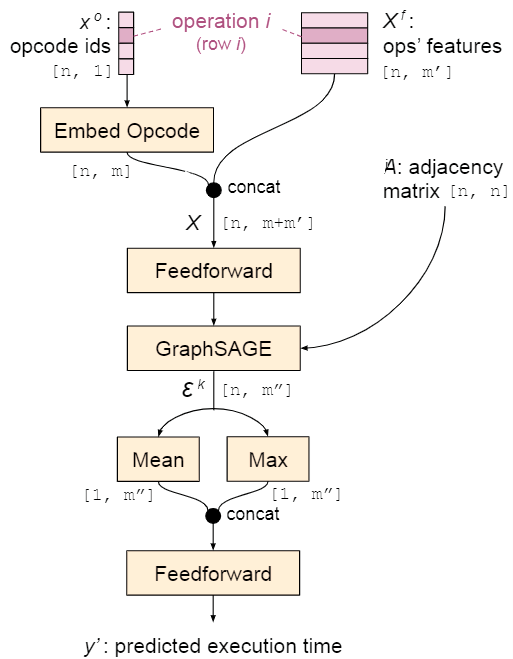
第个操作的操作码通过嵌入查找表嵌入为一个向量,一个操作的特征包含输出tensor形状、striding、padding、卷积核尺寸、tensor重叠等。然后使用一个前馈层接一个GraphSAGE合并操作码和操作特征信息,得到节点嵌入。之后,通过计算每一行的均值和最大值生成kernel嵌入,将均值和最大值向量的合并结果传入最终的前馈层生成kernel预测结果。
1)该工作考虑了框架在进行神经网络推理时算子间的影响,采用图嵌入的方式进行时延预测,比单层时延预测加和的模型时延预测准确;
2)该工作是基于学习的神经网络预测方法,计算和训练开销可能较大。
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
来 源:Computer Vision and Pattern Recognition 2019
原文速递:FBNet:Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
该工作致力于进行准确高效的神经网络搜索(NAS),注意到FLOP数并不总能准确地反映神经网络在设备上的推理时延。该工作测量了搜索空间内每个算子在设备上的运行时延,并使用一个标定表模型预测每个算子的时延,通过计算算子时延之和预测模型总时延。
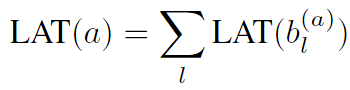
1)该方法考虑到时延预测的效率,采用标定表代替预测模型,是一种轻量级的方案;
2)该方法在设备转换时可能存在需要重新标定的问题,工作量较大;
3)该方法未考虑框架在运行时的算子融合,存在精度低的问题。
PALEO:A Performance Model for Deep Neural Networks
来 源:The International Conference on Learning Representations (ICLR) 2017
该工作通过分析DNN在设备上进行计算的过程对神经网络的推理时延进行预测,其建模方法如下图所示,分为计算时延和通信时延两部分,并综合考虑了网络结构和硬件配置。

该工作将每个神经网络节点的计算时延建模为三部分:获取父节点输入的时间、在设备上执行计算的时间、将模型输出写入内存的时延。
计算时延基于FLOPs计数和设备运行速度计算:,IO的时延通过计算内存占用/IO带宽获得。对于完整网络的时延预测,该工作通过计算所有层的时延和获得:。
1)该工作分析了在设备上进行推理需要的开销,能在一定程度上降低基于FLOPs时延预测的误差;
2)基于FLOPs的时延预测误差较大;
3)该工作对完整模型的时延预测方法采用多层时延的加和,未考虑算子融合机制,误差较大。
Predicting Execution Time of Computer Programs Using Sparse Polynomial Regression
来 源:NIPS’10: Proceedings of the 23rd International Conference on Neural Information Processing Systems - Volume 1December 2010 Pages 883–891
原文速递:Predicting Execution Time of Computer Programs Using Sparse Polynomial Regression
该工作侧重于对电脑应用程序运行时间的预测,与直接进行模型训练不同,其通过分析代码特性提取出多个程序的特征,并使用稀疏多项式回归模型预测程序运行时间。
稀疏多项式回归参考了LASSO的工作,从程序中可以分析出许多特征,如循环数、分支数、变量值等,而这些特征并不都对预测结果产生较大贡献,但大量的特征会使得多项式项数增多,降低预测效率。因此,可以将对结果影响小的特征的系数置零,只留下对结果影响大的特征子集。
1)该方法使用多项式模型预测程序运行时延,准确性优于基于FLOPs的线性模型;
2)该方法通过代码分析的方式预测电脑程序的运行时间,但对于神经网络的泛化性较差,许多代码并不开源,无法获得代码中的详细信息。
TVM:An Automated End-to-End Optimizing Compiler for Deep Learning
来 源:the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18). October 8–10, 2018 • Carlsbad, CA, USA
原文速递:TVM:An Automated End-to-End Optimizing Compiler for Deep Learning
该工作使用基于机器学习的代价模型,考虑到一个好的代价模型需要考虑影响性能的全部因素:内存访问模式、数据重用、管道依赖性等,现代硬件的复杂性高,并且针对每个新的目标硬件都需要新的代价模型,将是一个十分繁琐的过程。该方法在多轮预测的过程中测量模型实际运行时间,周期性地对模型进行更新,逐渐提高模型准确度。该方法在经过对比后使用梯度提升树模型(Gradient Tree Boosting Model),涉及到集中学习地范畴。
1)该方法通过运行时对模型的逐渐优化提高模型在不同设备上的可迁移性;
2)该方法完全基于机器学习,训练和计算开销较大。
Learning to Optimize Halide with Tree Search and Random Programs
来 源:ACM Transactions on Graphics, Volume 38, Issue 4, August 2019, Article No.: 121, pp 1–12 https://doi.org/10.1145/3306346.3322967
原文速递:Learning to Optimize Halide with Tree Search and Random Programs
该工作采用通过神经网络预测程序运行时间的方法,同时考虑到完全用网络进行黑盒预测需要一个很大的网络,并且很难训练,该工作的代价模型使用人工设计的项向量和小神经网络预测的系数向量点乘获得程序的运行时间。这些人工设计的项是特征的非线性组合,作者希望通过这样的设计方式使这些项与运行时间成比例地扩展。神经网络只需要调整每一项的权重,对于对最终表现无关的项,可将其系数置为0。
1)该方法考虑了预测器的预测效率,通过人工设计的多项式将预测网络变成小神经网络;
2)该方法需要考虑程序的代码特征,而对于非开源程序,该方法的泛化性较差。
HELP:Hardware-Adaptive Efficient Latency Prediction for NAS via Meta-Learning
来 源:35th Conference on Neural Information Processing Systems (NeurIPS 2021)
原文速递:HELP:Hardware-Adaptive Efficient Latency Prediction for Nas via Meta-Learning
该工作注意到许多工作的时延预测只针对特定设备进行设计,应用在每个新设备时都需要对模型重新训练,而每次训练都需要大量的测量数据,影响了NAS工作的效率。因此,该工作提出了一种基于元学习的硬件设备自适应时延预测器,在预测器部署到新设备时,只需要采集少量数据就可以实现模型迁移。
1)该工作考虑了预测模型在不同设备上的重新训练问题,使用元学习减少在不同设备上训练模型的代价;
2)该工作采用黑盒函数预测推理时延,要获得准确的预测结果需要复杂的函数,预测器效率不高。
Reducing energy consumption of Neural Architecture Search: An inference latency prediction framework
来 源:Sustainable Cities and Society Volume 67, April 2021, 102747
原文速递:Reducing energy consumption of Neural Architecture Search:An inference latency prediction framework
该工作关注于更好地进行NAS,避免在实际设备上多次运行神经网络造成的碳排放和能源消耗,通过时延预测器直接获得神经网络在目标设备上的性能情况。具体地,该工作使用LSTM网络进行特征提取,使用LightGBM进行时延回归。
1)该文参考了多种特征嵌入、预测模型,能够获得较高的预测精度;
2)该工作使用神经网络预测神经网络在设备上的时延,训练和预测的开销大,效率较低。
Generalized Latency Performance Estimation for Once-For-All Neural Architecture Search
来 源:CoRR abs/2101.00732 (2021)
原文速递:Generalized Latency Performance Estimation for Once-For-All Neural Architecture Search
该工作设计的时延预测器使用网络图嵌入的方式对神经网络进行训练,通过神经网络预测模型运行的时延。同时,该工作考虑到预测器在不同硬件设备上的泛化能力,将GPU被广泛使用的参数—核心数、内存尺寸、内存带宽加入到嵌入向量中进行训练,以便使模型能够快速部署到不同的硬件平台上,然后通过微调的方式使模型适应不同的硬件平台。
1)该工作采用图嵌入的方式进行时延预测,考虑了模型内部的内在联系,对模型块的时延预测更准确;
2)该工作完全使用神经网络预测模型运行时延,计算开销和模型尺寸都较大。
NNLQP:A Multi-Platform Neural Network Latency Query and Prediction System with An Evolving Database
来 源:ICPP ’22, August 29-September 1, 2022, Bordeaux, France
原文速递:NNLQP:A Multi-Platform Neural Network Latency Query and Prediction System with An Evolving Database
该工作为了降低在多各平台上进行模型运行时延采样的难度,设计时延查询系统,自动测量模型在目标硬件上的时延并存储到MySQL数据库上进行存储。为了获得准确的时延预测器,该工作使用统一的图嵌入方式将模型图和节点特征嵌入到one-hot向量中,并使用带有FC、Relu和Dropout层的网络训练时延预测器。应用到不同硬件设备时使用迁移学习的方式进行微调,提高模型的准确度。
1)该工作采用图嵌入的方式进行时延预测,考虑了模型内部的内在联系,对模型块的时延预测更准确;
2)该工作详细介绍了高效进行数据采样的方法,能获得大量用于模型训练的数据;
3)该工作完全使用神经网络预测模型运行时延,计算开销和模型尺寸都较大。
Predicting Latency of Neural Network Inference
来 源:CS230: Deep Learning, Fall 2020, Stanford University, CA.
该工作使用图嵌入的方式预测神经网络在CPU和GPU上的推理时延,使用展平的网络属性列表和邻接矩阵作为预测模型的输入,预测模型使用深度神经网络。为了找到合适的深度神经网络,该工作将每个隐藏层的数量设定为100,从1到20搜索隐藏层数量这个超参数,使用在验证集上绝对误差最小的超参数。

1)该工作将模型图结构嵌入作为预测模型的输入,相较于层级别的时延预测,准确度更高;
2)该方法对于不同硬件平台的泛化能力较差,更换平台后训练代价高;
3)该工作使用的预测模型是黑盒的,模型较大,预测效率低。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.