

1. 引言
PyTorch是Facebook团队于2017年1月发布的一个深度学习框架,虽然晚于TensorFlow、Keras等框架,但自发布之日起,其关注度就在不断上升,目前在GitHub上的热度已超过Theano、Caffe、MXNet等框架。
PyTorch是一个建立在Torch库之上的Python包,旨在加速深度学习应用。它提供一种类似Numpy的抽象方法来表征张量(或多维数组),可以利用GPU来加速训练。由于PyTorch采用了动态计算图(Dynamic Computational Graph)结构,且基于tape的Autograd系统的深度神经网络。其他很多框架,比如TensorFlow(TensorFlow2.0也加入了动态网络的支持)、Caffe、CNTK、Theano等,采用静态计算图。使用PyTorch,通过一种称为Reverse-mode auto-differentiation(反向模式自动微分)的技术,可以零延迟或零成本地任意改变你的网络的行为。
Torch是PyTorch中的一个重要包,它包含了多维张量的数据结构以及基于其上的多种数学操作。
自2015年谷歌开源TensorFlow以来,深度学习框架之争越来越激烈,全球多个看重AI研究与应用的科技巨头均在加大这方面的投入。PyTorch从2017年年初发布以来,可谓是异军突起,短时间内取得了一系列成果,成为明星框架。
PyTorch由4个主要的包组成:
torch:类似于Numpy的通用数组库,可将张量类型转换为torch.cuda.TensorFloat,并在GPU上进行计算;
torch.autograd:用于构建计算图形并自动获取梯度的包;
torch.nn:具有共享层和损失函数的神经网络库;
torch.optim:具有通用优化算法(如SGD、Adam等)的优化包。
2. Numpy与Tensor
上一内容介绍了Numpy,了解到其存取数据非常方便,而且还拥有大量的函数,所以深得数据处理、机器学习者喜爱。这节内容将介绍PyTorch的Tensor,它可以是零维(又称为标量或一个数)、一维、二维及多维的数组。Tensor自称为神经网络界的Numpy,它与Numpy相似,二者可以共享内存,且之间的转换非常方便和高效。不过它们也有不同之处,最大的区别就是Numpy会把ndarray放在CPU中进行加速运算,而由Torch产生的Tensor会放在GPU中进行加速运算(假设当前环境有GPU)。
2.1 创建Tensor
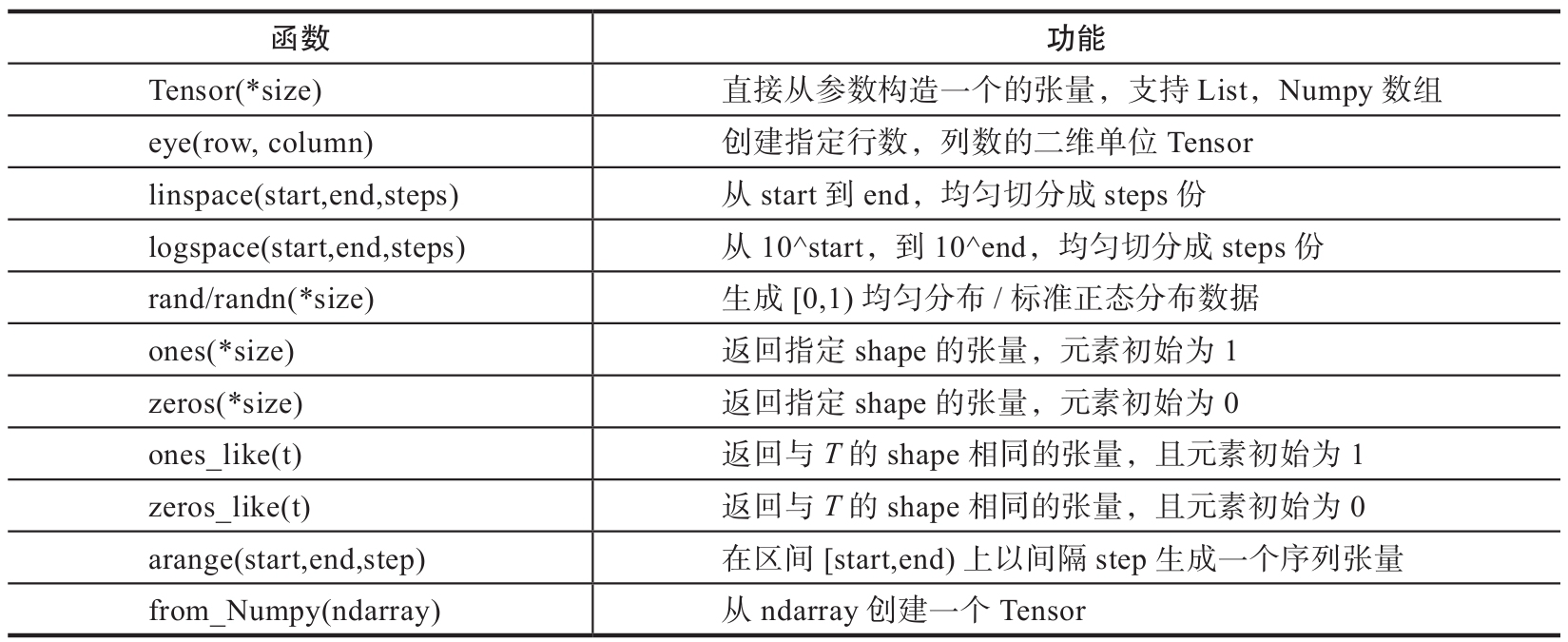
创建Tensor的方法有很多,可以从列表或ndarray等类型进行构建,也可根据指定的形状构建。常见的创建Tensor的方法可参考表1。
1 | import torch |
1 | #生成一个单位矩阵 |
2.2 修改Tensor形状
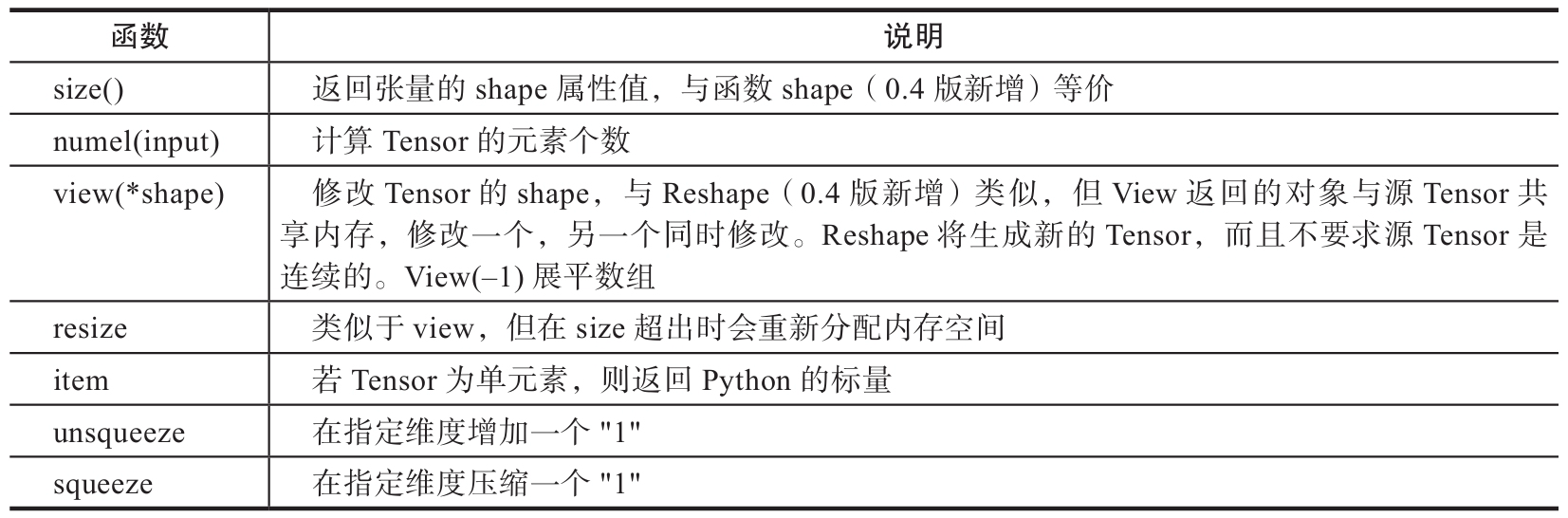
在处理数据、构建网络层等过程中,经常需要了解Tensor的形状、修改Tensor的形状。与修改Numpy的形状类似,修改Tenor的形状也有很多类似函数,具体可参考表2。
1 | #生成一个形状为2x3的矩阵 |
torch.view与torch.reshpae的异同
1)reshape()可以由torch.reshape(),也可由torch.Tensor.reshape()调用。但view()只可由torch.Tensor.view()来调用;
2)对于一个将要被view的Tensor,新的size必须与原来的size与stride兼容。否则,在view之前必须调用contiguous()方法;
3)同样也是返回与input数据量相同,但形状不同的Tensor。若满足view的条件,则不会copy,若不满足,则会copy;
4)如果你只想重塑张量,请使用torch.reshape。如果你还关注内存使用情况并希望确保两个张量共享相同的数据,请使用torch.view。
2.3 索引操作
Tensor的索引操作与Numpy类似,一般情况下索引结果与源数据共享内存。从Tensor获取元素除了可以通过索引,也可以借助一些函数,常用的选择函数可参考表3。

1 | 设置一个随机种子 |
2.4 广播机制
广播机制是向量运算的重要技巧。除了Numpy支持广播机制外,PyTorch也支持广播机制。
1 | import torch |
2.5 逐元素操作
与Numpy一样,Tensor也有逐元素操作(Element-Wise),且操作内容相似,但使用函数可能不尽相同。大部分数学运算都属于逐元素操作,其输入与输出的形状相同。常见的逐元素操作可参考表4。
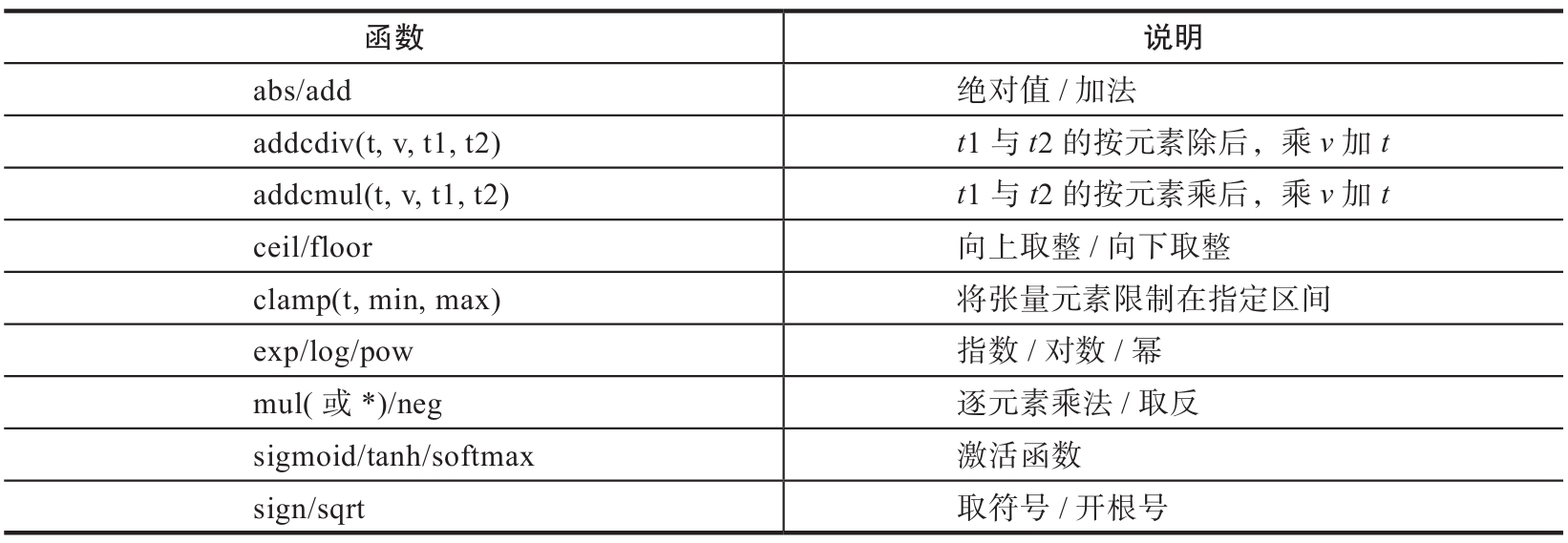
这些操作均会创建新的Tensor,如果需要就地操作,可以使用这些方法的下划线版本,例如abs_。
1 | t = torch.randn(1, 3) |
2.6 归并操作
归并操作顾名思义,就是对输入进行归并或合计等操作,这类操作的输入输出形状一般并不相同,而且往往是输入大于输出形状。归并操作可以对整个Tensor,也可以沿着某个维度进行归并。常见的归并操作可参考表5。
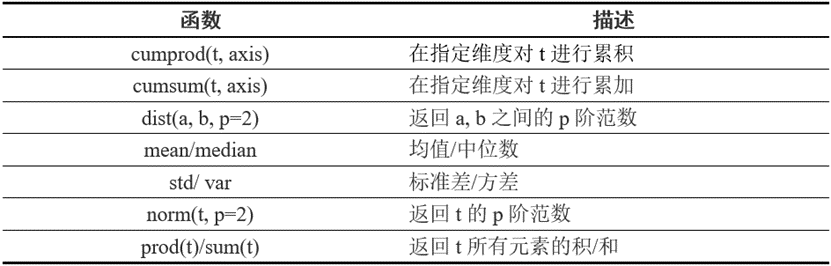
归并操作一般涉及一个dim参数,指定沿哪个维进行归并。另一个参数是keepdim,说明输出结果中是否保留维度1,缺省情况是False,即不保留。
1 | #生成一个含6个数的向量 |
2.7 比较操作
比较操作一般是进行逐元素比较,有些是按指定方向比较。常用的比较函数可参考表6。
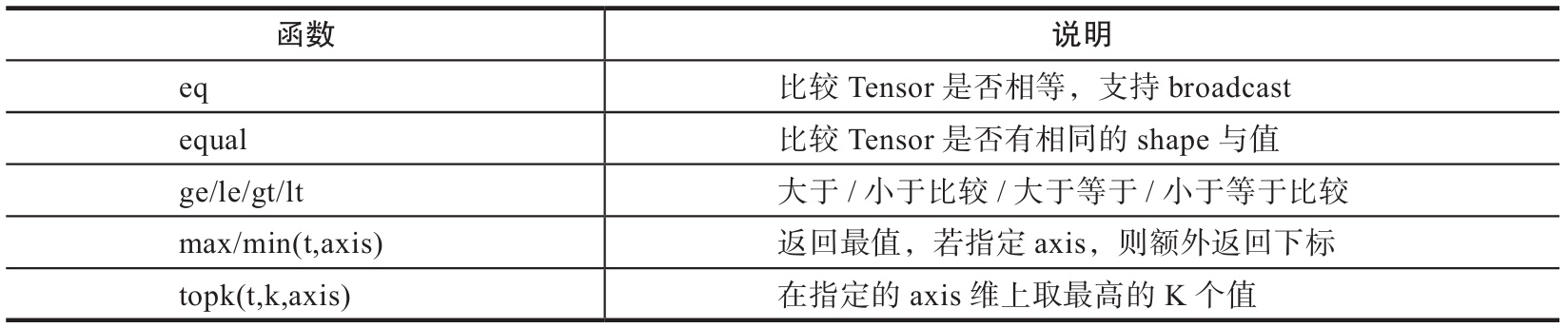
1 | x=torch.linspace(0,10,6).view(2,3) |
2.8 矩阵操作
机器学习和深度学习中存在大量的矩阵运算,常用的算法有两种:一种是逐元素乘法,另外一种是点积乘法。PyTorch中常用的矩阵函数可参考表7。
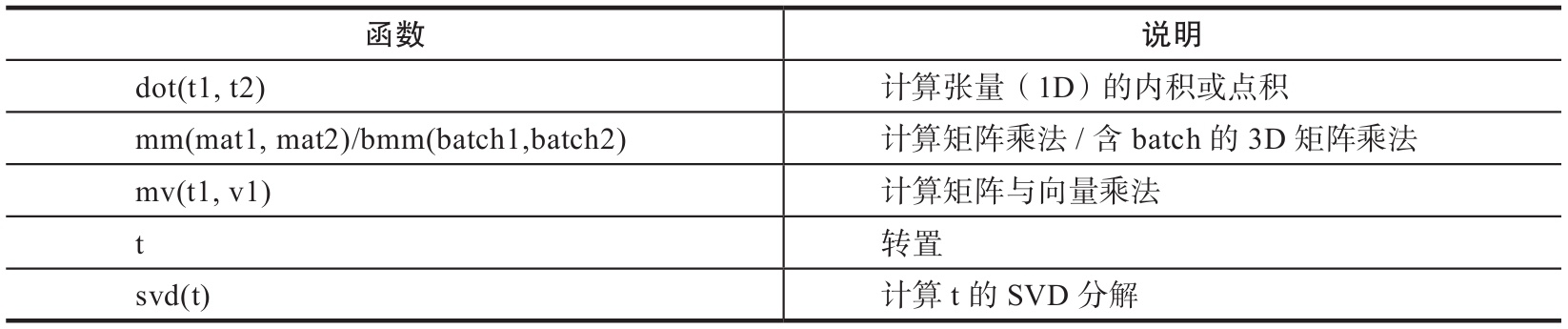
1)Torch的dot与Numpy的dot有点不同,Torch中的dot是对两个为1D张量进行点积运算,Numpy中的dot无此限制;
2)mm是对2D的矩阵进行点积,bmm对含batch的3D矩阵进行点积运算;
3)转置运算会导致存储空间不连续,需要调用contiguous方法转为连续。
1 | a=torch.tensor([2, 3]) |
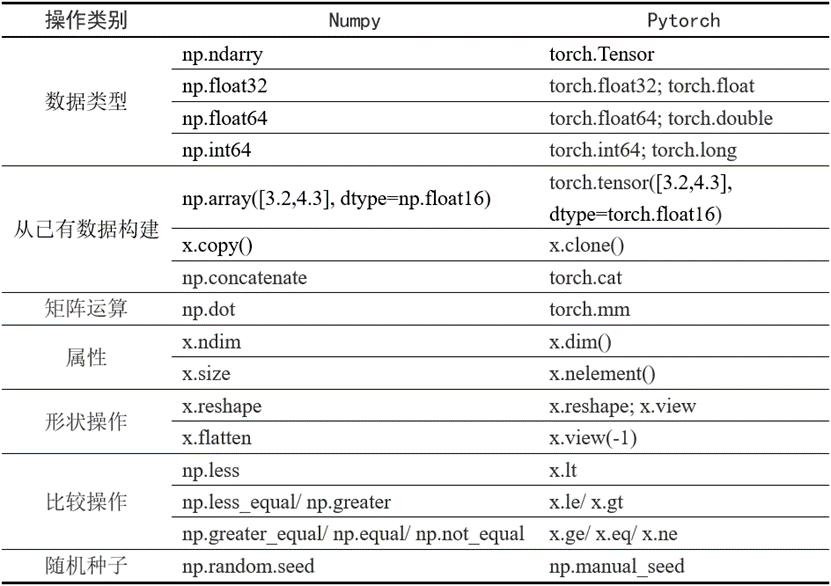
2.9 PyTorch与Numpy比较
PyTorch与Numpy有很多类似的地方,并且有很多相同的操作函数名称,或虽然函数名称不同但含义相同;当然也有一些虽然函数名称相同,但含义不尽相同。有些很容易混淆,Numpy与Pytorch函数的一些主要区别可参考表8。
3. 使用Tensor及Autograd实现机器学习
在神经网络中,一个重要内容就是进行参数学习,而参数学习离不开求导,那么PyTorch是如何进行求导的呢?
现在大部分深度学习架构都有自动求导的功能,PyTorch也不例外,torch.autograd包就是用来自动求导的。Autograd包为张量上所有的操作提供了自动求导功能,而torch.Tensor和torch.Function为Autograd的两个核心类,它们相互连接并生成一个有向无环图(DAG)。
本节将使用PyTorch的autograd自动求导包及对应的Tensor,利用自动反向传播来求梯度,无须手工计算梯度。
1)导入需要的库。
1 | import torch |
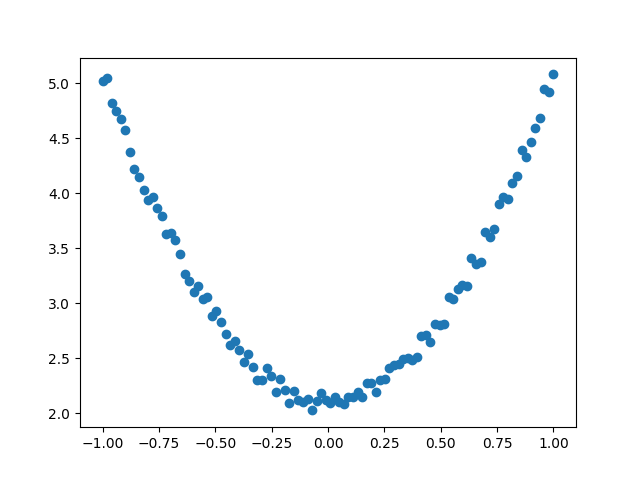
2)生成训练数据,并可视化数据分布情况。
1 | t.manual_seed(100) |
3)初始化权重参数。
1 | # 随机初始化参数,参数w、b为需要学习的,故需requires_grad=True |
4)训练模型。
1 | lr =0.001 # 学习率 |
5)可视化训练结果。
1 | plt.plot(x.numpy(), y_pred.detach().numpy(),'r-',label='predict')#predict |
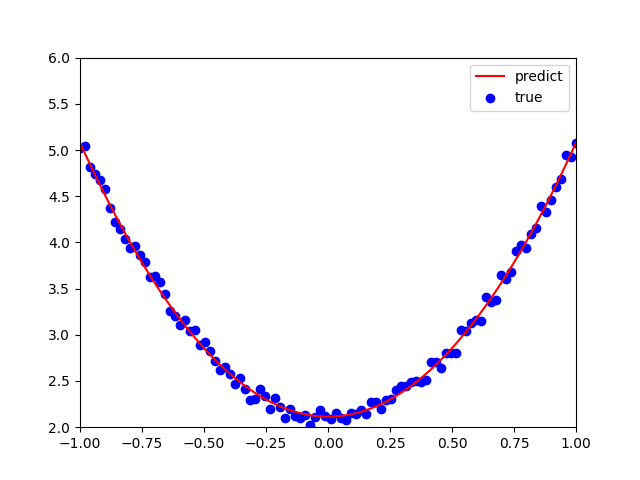
1 | 运行结果: |
4. PyTorch神经网络工具箱
4.1 神经网络核心组件
神经网络看起来很复杂,节点很多,层数多,参数更多。但核心部分或组件不多,把这些组件确定后,这个神经网络基本就确定了。这些核心组件包括:
1)层:神经网络的基本结构,将输入张量转换为输出张量。
2)模型:层构成的网络。
3)损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。
4)优化器:如何使损失函数最小,这就涉及优化器。
当然这些核心组件不是独立的,它们之间,以及它们与神经网络其他组件之间有密切关系。为便于读者理解,我们可以把这些关键组件及相互关系,用图1表示。
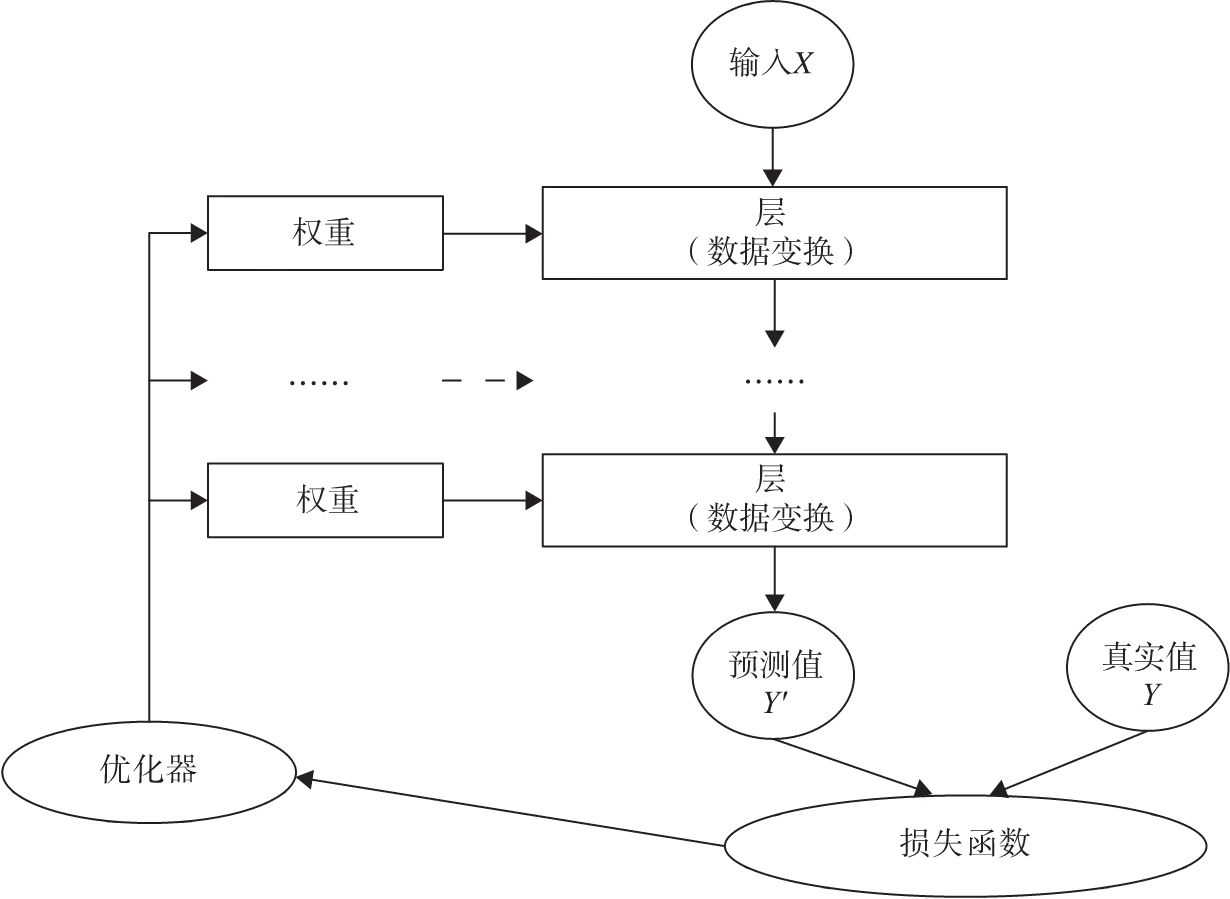
多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似程度,优化器利用损失值更新权重参数,从而使损失值越来越小。这是一个循环过程,当损失值达到一个阀值或循环次数到达指定次数,循环结束。
4.2 神经网络工具箱nn
前面我们使用Autograd及Tensor实现机器学习实例时,需要做不少设置,如对叶子节点的参数requires_grad设置为True,然后调用backward,再从grad属性中提取梯度。对于大规模的网络,Autograd太过于底层和烦琐。为了简单、有效解决这个问题,nn是一个有效工具。在nn工具箱中有两个重要模块:nn.Model、nn.functional。
nn中的大多数层(Layer)在functional中都有与之对应的函数。nn.functional中函数与nn.Module中的Layer的主要区别是后者继承Module类,会自动提取可学习的参数。而nn.functional更像是纯函数。两者功能相同,且性能也没有很大区别,那么如何选择呢?像卷积层、全连接层、Dropout层等因含有可学习参数,一般使用nn.Module,而激活函数、池化层不含可学习参数,可以使用nn.functional中对应的函数。
4.2.1 nn.Module
nn.Module是nn的一个核心数据结构,它可以是神经网络的某个层(Layer),也可以是包含多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,生成自己的网络/层。nn中已实现了绝大多数层,包括全连接层、损失层、激活层、卷积层、循环层等,这些层都是nn.Module的子类,能够自动检测到自己的Parameter,并将其作为学习参数,且针对GPU运行进行了cuDNN优化。
4.2.2 nn.functional
nn中的层,一类是继承了nn.Module,其命名一般为nn.Xxx(第一个是大写),如nn.Linear、nn.Conv2d、nn.CrossEntropyLoss等。另一类是nn.functional中的函数,其名称一般为nn.funtional.xxx,如nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。从功能来说两者相当,基于nn.Moudle能实现的层,使用nn.funtional也可实现,反之亦然,而且性能方面两者也没有太大差异。不过在具体使用时,两者还是有区别,主要区别如下:
1)nn.Xxx继承于nn.Module,nn.Xxx需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据。它能够很好地与nn.Sequential结合使用,而nn.functional.xxx无法与nn.Sequential结合使用。
2)nn.Xxx不需要自己定义和管理weight、bias参数;而nn.functional.xxx需要自己定义weight、bias参数,每次调用的时候都需要手动传入weight、bias等参数,不利于代码复用。
3)Dropout操作在训练和测试阶段是有区别的,使用nn.Xxx方式定义Dropout,在调用model.eval()之后,自动实现状态的转换,而使用nn.functional.xxx却无此功能。
总的来说,两种功能都是相同的,但PyTorch官方推荐:具有学习参数的(例如,conv2d,linear,batch_norm)采用nn.Xxx方式。没有学习参数的(例如,maxpool、loss func、activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。
4.3 优化器
PyTorch常用的优化方法都封装在torch.optim里面,其设计很灵活,可以扩展为自定义的优化方法。所有的优化方法都是继承了基类optim.Optimizer,并实现了自己的优化步骤。最常用的优化算法就是梯度下降法及其各种变种,这类优化算法通过使用参数的梯度值更新参数。
使用优化器的一般步骤为:
(1)建立优化器实例
导入optim模块,实例化SGD优化器,这里使用动量参数momentum(该值一般在(0,1)之间),是SGD的改进版,效果一般比不使用动量规则的要好。
1 | import torch.optim as optim |
以下步骤在训练模型的for循环中。
(2)向前传播
把输入数据传入神经网络Net实例化对象model中,自动执行forward函数,得到out输出值,然后用out与标记label计算损失值loss。
1 | out = model(img) |
(3)清空梯度
缺省情况梯度是累加的,在梯度反向传播前,先需把梯度清零。
1 | optimizer.zero_grad() |
(4)反向传播
基于损失值,把梯度进行反向传播。
1 | loss.backward() |
(5)更新参数
基于当前梯度(存储在参数的.grad属性中)更新参数。
1 | optimizer.step() |
动态修改学习率参数
修改参数的方式可以通过修改参数optimizer.params_groups或新建optimizer。新建optimizer比较简单,optimizer十分轻量级,所以开销很小。但是新的优化器会初始化动量等状态信息,这对于使用动量的优化器(momentum参数的SGD)可能会造成收敛中的震荡。所以,这里直接采用修改参数optimizer.params_groups。
optimizer.param_groups:长度1的list,optimizer.param_groups[0]:长度为6的字典,包括权重参数、lr、momentum等参数。
1 | len(optimizer.param_groups[0]) |
动态修改学习率参数示例:
1 | for epoch in range(num_epoches): |
4.4 神经网络构建实例
使用PyTorch构建神经网络使用的主要工具(或类)及相互关系如图2所示。如4.2节所述,构建网络层可基于Module类或函数(nn.functional)。
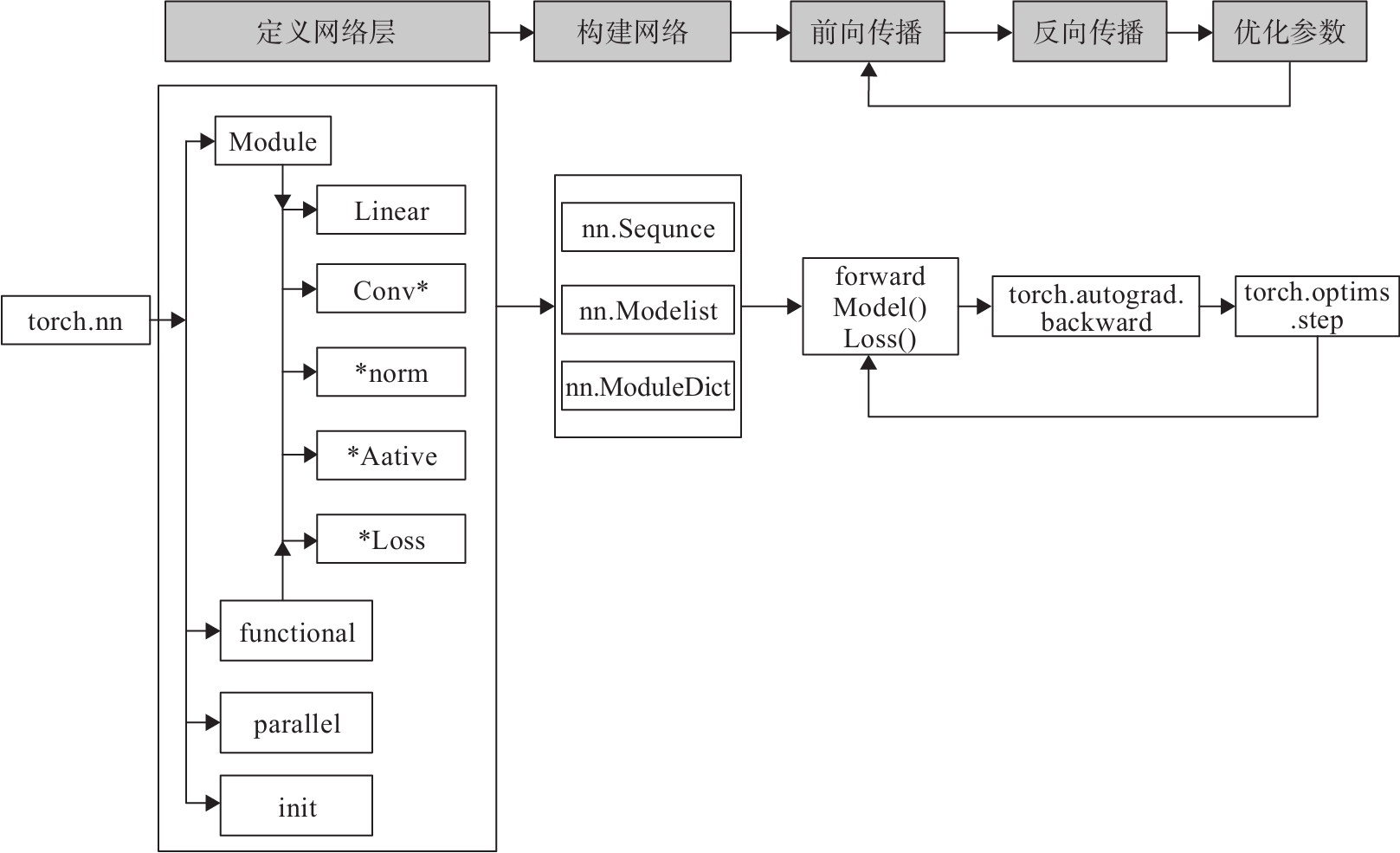
下面将利用神经网络完成对手写数字进行识别的实例,来说明如何借助nn工具箱来实现一个神经网络,并对神经网络有个直观了解。主要步骤有:
1)利用PyTorch内置函数mnist下载数据集;
2)利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器;
3)可视化源数据;
4)利用nn工具箱构建神经网络模型;
5)实例化模型,并定义损失函数及优化器;
6)训练模型;
7)可视化结果。
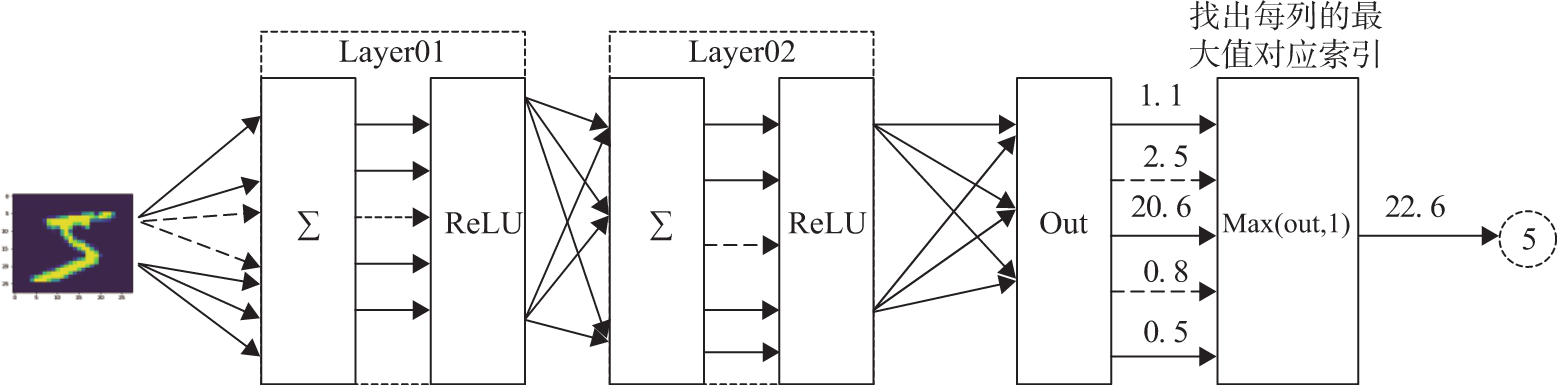
神经网络的结构如图3所示,使用两个隐含层,每层激活函数为ReLU,最后使用torch.max(out,1)找出张量out最大值对应索引作为预测值。
4.4.1 数据准备
(1)导入模块
1 | import numpy as np |
(2)定义超参数
1 | train_batch_size = 64 |
(3)下载数据并对数据进行预处理
1 | #定义预处理函数,这些预处理依次放在Compose函数中。 |
1)transforms.Compose可以把一些转换函数组合在一起;
2)Normalize([0.5],[0.5])对张量进行归一化,这里两个0.5分别表示对张量进行归一化的全局平均值和方差。因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如3个通道,应该是Normalize([m1,m2,m3],[n1,n2,n3]);
3)download参数控制是否需要下载,如果./data目录下已有MNIST,可选择False;
4)用DataLoader得到生成器,这可节省内存;
5)shuffle=True表示对数据进行打乱操作。
4.4.2 可视化源数据
1 | examples = enumerate(test_loader) |

4.4.3 模型构建
(1)构建网络
1 | class Net(nn.Module): |
(2)实例化网络
1 | #检测是否有可用的GPU,有则使用,否则使用CPU |
4.4.4 模型训练
这里使用for循环进行迭代,其中包括对训练数据的训练模型,然后用测试数据的验证模型。
(1)模型训练
1 | # 开始训练 |
迭代结果:
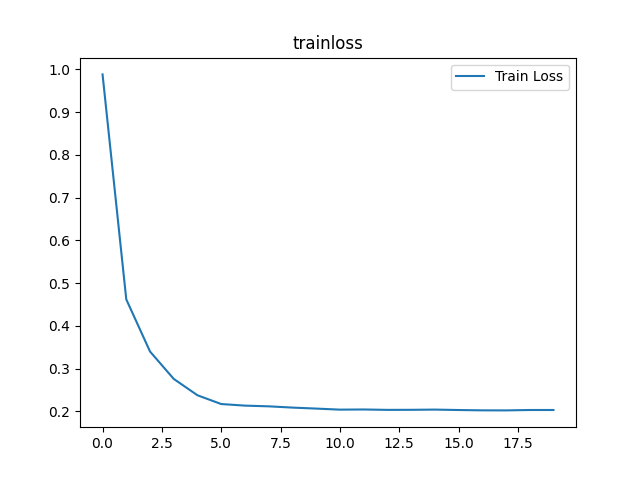
1 | epoch:0, Train Loss:0.9885, Train Acc:0.7987, Test Loss:0.5235, Test Acc:0.9073 |
该神经网络的结构比较简单,只用了两层,也没有使用Dropout层,迭代20次,测试准确率达到98%左右,效果还可以。不过,还是有提升空间,如果采用cnn、Dropout等层,应该还可以提升模型性能。
(2)可视化训练及测试损失值
1 | plt.title('trainloss') |
5. PyTorch数据处理工具箱
上节利用PyTorch的torchvision、data等包,下载及预处理MNIST数据集。数据下载和预处理是机器学习、深度学习实际项目中耗时又重要的任务,尤其是数据预处理,关系到数据质量和模型性能,往往要占据项目的大部分时间。好在PyTorch为此提供了专门的数据下载、数据处理包,使用这些包,可极大地提高我们的开发效率及数据质量。
PyTorch涉及数据处理(数据装载、数据预处理、数据增强等)主要工具包及相互关系如图4所示。
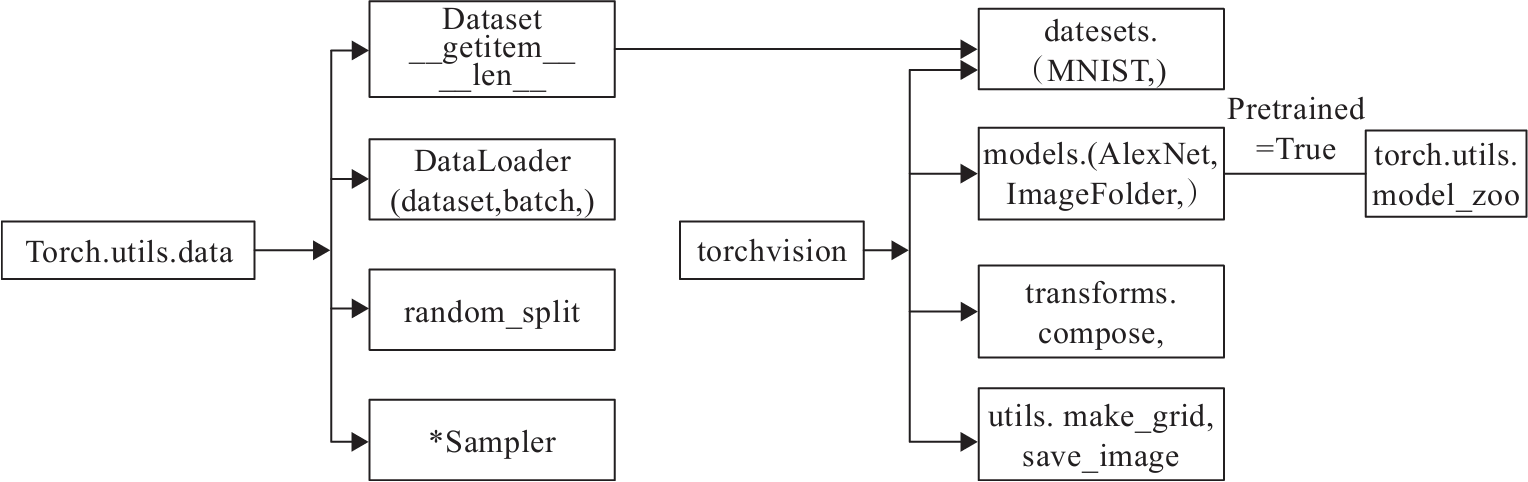
图4的左边是torch.utils.data工具包,它包括以下4个类。
1)Dataset:是一个抽象类,其他数据集需要继承这个类,并且覆写其中的两个方法(_getitem、len__);
2)DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能;
3)random_split:把数据集随机拆分为给定长度的非重叠的新数据集;
4)*sampler:多种采样函数。
图4中间是PyTorch可视化处理工具(Torchvision),其是PyTorch的一个视觉处理工具包,独立于PyTorch,需要另外安装。它包括4个类,各类的主要功能如下。
1)datasets:提供常用的数据集加载,设计上都是继承自torch.utils.data.Dataset,主要包括MMIST、CIFAR10/100、ImageNet和COCO等;
2)models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择pretrained=True),包括AlexNet、VGG系列、ResNet系列、Inception系列等;
3)transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作;
4)utils:含两个函数,一个是make_grid,它能将多张图片拼接在一个网格中;另一个是save_img,它能将Tensor保存成图片。
5.1 utils.data
utils.data包括Dataset和DataLoader。torch.utils.data.Dataset为抽象类,自定义数据集需要继承这个类,并实现两个函数,一个是__len__,另一个是__getitem,前者提供数据的大小(size),后者通过给定索引获取数据和标签。\getitem__一次只能获取一个数据,所以需要通过torch.utils.data.DataLoader来定义一个新的迭代器,实现batch读取。下面定义一个简单的数据集,然后通过具体使用Dataset及DataLoader,获得一个直观的认识。
(1)导入需要的模块。
1 | import torch |
(2)定义获取数据集的类。
该类继承基类Dataset,自定义一个数据集及对应标签。
1 | class TestDataset(data.Dataset):#继承Dataset |
(3)获取数据集中数据。
1 | Test=TestDataset() |
输出结果:
1 | (tensor([2, 1]), tensor(0)) |
以上数据以tuple返回,每次只返回一个样本。实际上,Dateset只负责数据的抽取,调用一次__getitem__只返回一个样本。如果希望批量处理(batch),还要同时进行shuffle和并行加速等操作,可选择DataLoader。DataLoader的格式为:
1 | data.DataLoader( |
主要参数说明:
dataset:加载的数据集;
batch_size:批大小;
shuffle:是否将数据打乱;
sampler:样本抽样;
num_workers:使用多进程加载的进程数,0代表不使用多进程;
collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可;
pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些;
drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
1 | test_loader = data.DataLoader(Test,batch_size=2,shuffle=False,num_workers=0) |
运行结果:
1 | i: 0 |
可以看出,这是批量读取,可以像使用迭代器一样使用它,比如对它进行循环操作。不过由于它不是迭代器,我们可以通过iter命令将其转换为迭代器。
1 | dataiter=iter(test_loader) |
5.2 torchvision
如图4所示,torchvision有4个功能模块:model、datasets、transforms和utils,上文中使用datasets下载了一些经典数据集,本节介绍如何使用datasets的ImageFolder处理数据集,以及如何使用transforms对数据进行预处理、增强等。
5.2.1 ImageFolder
当文件依据标签处于不同文件下时,如:
─── data
├── zhangliu
│ ├── 001.jpg
│ └── 002.jpg
├── wuhua
│ ├── 001.jpg
│ └── 002.jpg
……………..
可以利用torchvision.datasets.ImageFolder来直接构造出dataset:
1 | loader = datasets.ImageFolder(path, transform=None) |
ImageFolder会将目录中的文件夹名自动转化成序列,当DataLoader载入时,标签自动就是整数序列了。
5.2.2 transforms
transforms提供了对PIL Image对象和Tensor对象的常用操作。
(1)对PIL Image的常见操作
Scale/Resize:调整尺寸,长宽比保持不变;
CenterCrop、RandomCrop、RandomSizedCrop:裁剪图片,CenterCrop和RandomCrop在crop时是固定size,RandomResizedCrop则是random size的crop;
Pad:填充;
ToTensor:把一个取值范围是[0,255]的PIL.Image转换成Tensor。形状为(H,W,C)的Numpy.ndarray转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloatTensor;
RandomHorizontalFlip:图像随机水平翻转,翻转概率为0.5;
RandomVerticalFlip:图像随机垂直翻转;
ColorJitter:修改亮度、对比度和饱和度。
(2)对Tensor的常见操作
Normalize:标准化,即,减均值,除以标准差;
ToPILImage:将Tensor转为PIL Image。
如果要对数据集进行多个操作,可通过Compose将这些操作像管道一样拼接起来,类似于nn.Sequential。
1 | transforms.Compose([ |
本内容旨在为读者提供PyTorch的一些主要基础内容,仅包含PyTorch完整内容的一部分,欲学习更多PyTorch相关内容,请查看:https://pytorch.org/docs/stable/index.html
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.