

来 源:EuroSys ‘19: Proceedings of the Fourteenth EuroSys Conference 2019 - March 2019 - Article No.: 45 - Pages 1–15 https://doi.org/10.1145/3302424.3303950
1. Background & Motivation
随着神经网络(NN)的发展,移动服务供应商在移动设备上部署了许多服务,比如Google的手写转文字功能、Google的即时翻译、YouTube的视频分割以及Google、Apple等公司的虚拟助手。而为满足这些应用的时延要求,传统的做法是依赖于丰富的云端资源实现的。然而,随着高性能的移动端SoC的出现,完全依赖移动端设备进行神经网络推理成为可能。由于强响应性对移动服务至关重要,高效利用移动设备资源是十分必要的。
通过更好地利用移动设备硬件资源,对轻量神经网络的几乎实时响应成为可能,但由于时延问题,大部分移动服务仍然依赖云端资源,比如所有实际的虚拟助手都将工作卸载到云端进行语音识别。而现在的Soc上具有多种资源,实现快速准确的设备上推理是可行的。
2. Contributions
1)发现协同实现神经网络单层加速的潜力。该文发现现代SoC上的CPU和GPU具有平衡的吞吐量,使CPU-GPU协同神经网络加速成为可能;
2)提出新的协同单层加速机制。通过从多维度对神经网络执行进行优化,获得相比先进方法的时延降低;
3)设计μLayer系统。提出一个优化的神经网络架构μLayer用于减小神经网络的执行时延。
3. Design Details
3.1 协同单层加速
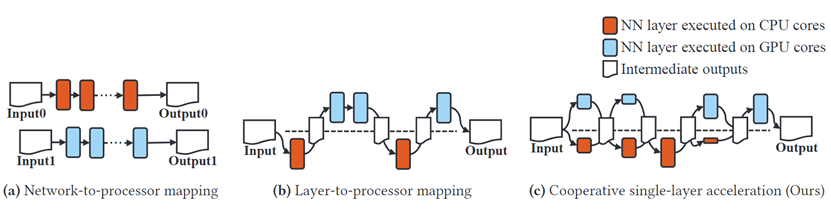
如图1(a)、(b)所示,现有移动神经网络框架由于只利用单一处理器限制了性能,而本文提出的框架能够在CPU和GPU上协同执行神经网络中的层。
该文提出通道级工作负载分配方法如图2所示,其可以避免引入CPU和GPU间的冗余计算。
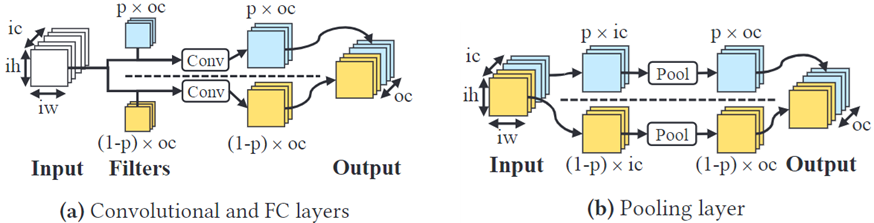
对于卷积层和全连接层,filter被以的比例分配给各处理器,完整的输入数据将被分配给各处理器进行计算,最后计算出的输出通道被合并生成输出数据。对于池化层,输入数据被分配给各处理器,每个处理器对自己的数据部分使用全局函数进行计算,最后的结果将被合并。
3.2 针对处理器的量化
为了优化每个处理器的性能表现,该文考虑了2种量化方案:16位半精度浮点数(F16)和8位线性量化(QUInt8)。因为GPU在实现高吞吐量的浮点运算方面有本地硬件支持,对GPU使用16位半精度浮点数量化。CPU更擅长处理QUInt8类型的数据,因此对其使用8位线性量化。
3.3 分支分配
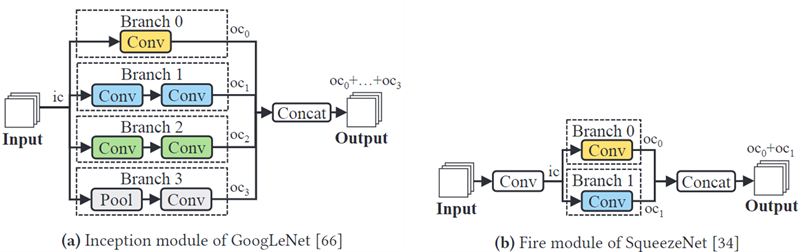
现有的一些神经网络(如GoogLeNet)包含分支结构,如图3。这些分支可能会影响通道级工作负载分配的性能。而多分支结构的时延可通过并行运行多个分支来隐藏,即同一分支上的多个层将在一个处理器上运行。
3.4 μLayer运行时架构
如图4,μLayer由3个部件组成:一个神经网络分割器、一个时延预测器和一个神经网络执行器。
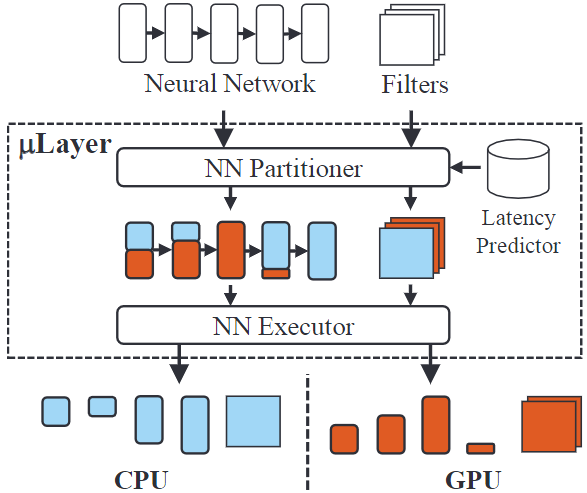
神经网络分割器负责协同执行计划的生成,对于每一层,神经网络分割器决定通道分割的比例,神经网络分割器根据时延预测器找出最优的值。
时延预测器能够根据每层神经网络的参数(如输入尺寸和filter尺寸)以及值预测该层的执行时延。该文在Neurosurgeon(Paper Link)设计的时延预测器基础上引入参数,首先对CPU和GPU独立执行运用指数回归方法拟合模型,然后通过给定的值调整时延预测值。时延预测器将时延预测值反馈给神经网络分割器选出分割方案,最后神经网络执行器根据最优分割方案在CPU和GPU间协同进行神经网络推理。
4. Comments
该文致力于通过CPU-GPU协同执行的方式进行高效神经网络推理,设计了一种层级协同推理方法,能够取得一定的性能提升,但仍存在一些问题:
1)该系统中的时延预测器采用机器学习拟合函数,与Neurosurgeon相同,存在精度低的问题;
2)该CPU-GPU协同方法是层粒度的,存在高频同步的问题,而由于时延预测器的不准确性会造成CPU,GPU的运行差异,同步开销可能会成为时延的主体部分。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.