

来 源:MobiSys ‘22: Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and ServicesJune 2022 Pages 209–221https://doi.org/10.1145/3498361.3538932
原文速递:CoDL:Efficient CPU-GPU Co-execution for Deep Learning Inference on Mobile Devices
1.Background & Motivation
当前,深度学习已经成为众多移动应用的支柱。由于隐私性,网络弹性和云计算开销上的优势,在边缘设备上进行推理成为一种趋势。然而,边缘设备的性能有限,只有在推理轻量小模型时才能获得能够容忍的推理速度,比如在移动处理器上运行YOLO目标检测网络具有超200ms的延时。为了能够在移动设备上缩短大模型推理的时延,该文致力于同时利用移动设备上的CPU和GPU来加速推理。该方案可行的两个主要原因是:
1)与运行速度比CPU快一个数量级的服务器GPU不同,移动CPU和GPU在DL推理上具有近似的性能,因此可以进行并行推理;
2)与服务器上CPU和GPU有独立的内存不同,移动设备的CPU和GPU具有统一的内存空间,可以避免不同内存间的数据复制。
然而,现有的协同执行系统存在以下问题:
1)在不同的处理器间使用相同的数据类型。统一的数据类型在多种处理器上的处理效率是不同的,如图1,在Adreno GPU上使用Image类型的数据比buffer类型更高效;
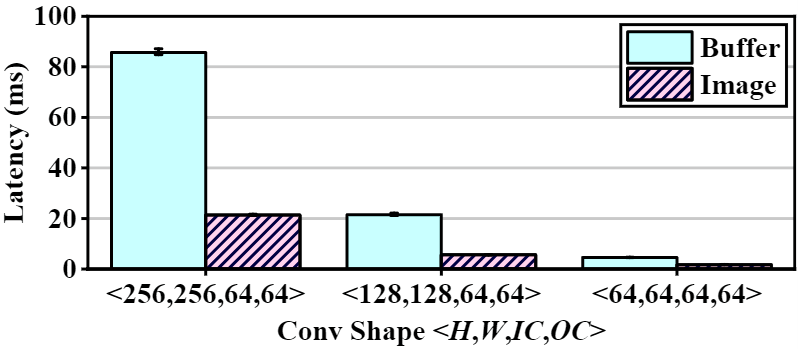
图1 使用buffer和image数据类型进行3×3卷积的时延对比 2)处理器间的数据传输开销是不可忽视的,特别是对于小尺寸的算子。如图2,CPU和GPU并行推理存在数据类型转换(DT)、数据映射(M)、同步(Pre-sync & Post-sync)和数据解映射四种额外开销。对于小算子,额外开销可能会占据总开销的主要部分(图3);
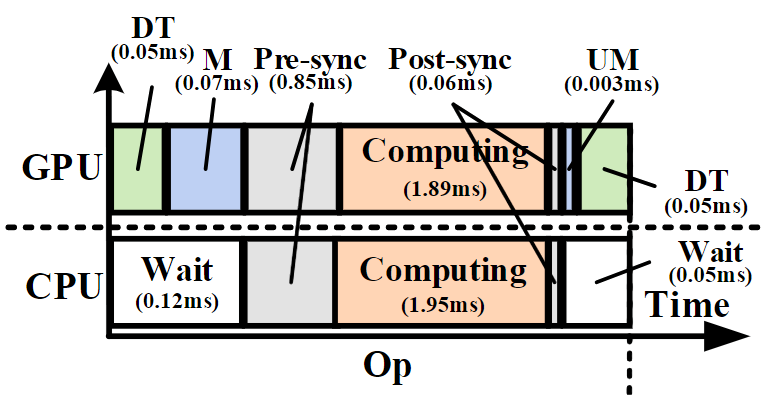
图2 CPU-GPU协同执行的时延组成 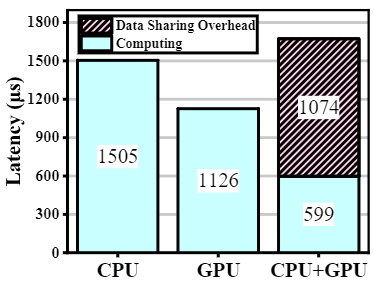
图3 形状为<52,52,256,128>的1×1卷积的计算时延和数据共享开销 3)平衡的工作负载分割需要轻量且准确的时延预测器。现有协同执行系统大都使用轻量的时延预测模型去指导工作负载的切分,然而如表1所示,轻量的模型虽然适合于在线预测,但准确性很差(<10%),这是由于执行的时延并不是FLOPs的线性函数,而是受平台特性影响的(图4)。同时,还有一些工作致力于准确的时延预测,例如nn-Meter,但由于缺乏对部署平台特性的知识,其获得高精度的代价是需要运行大规模模型,不适合在移动设备上部署。
表1 两种时延预测器的±10%准确度和模型尺寸 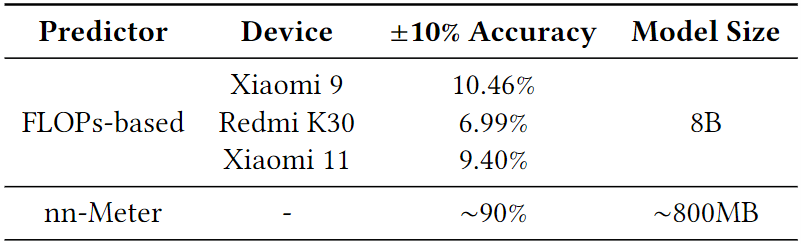
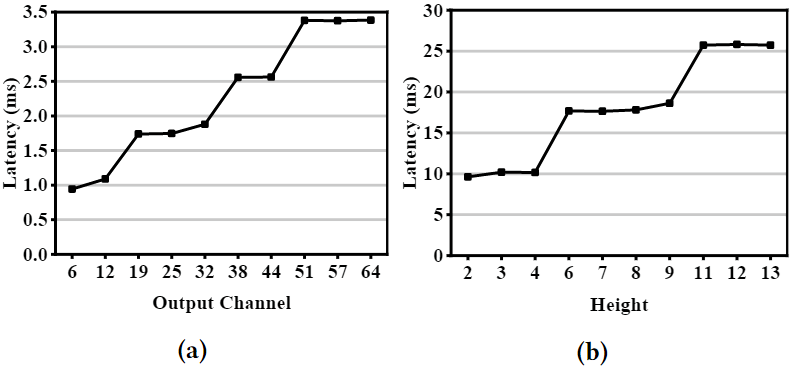
图4 (a)GPU(b)CPU对FLOPs增加表现出的非线性
2. Contributions
1)深入分析CPU+GPU协同推理的性能瓶颈;
2)提出CPU和GPU间的多类型数据共享机制,通过设计多维分割和算子链来减小数据共享开销;
3)提出轻量的准确时延预测方法;
4)在设备上部署端到端的CoDL框架,验证其相较于SOTA方案的优点。
3.Design Details
CoDL的系统设计遵循三个原则:
1)充分利用每个处理器的计算能力;
2)最小化数据共享的额外开销;
3)多种处理器间的工作负载最优分割。
CoDL的系统架构和工作流程如图5所示,其由离线和在线两个阶段组成。
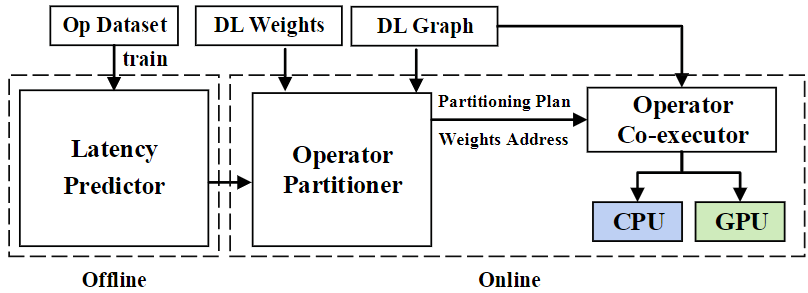
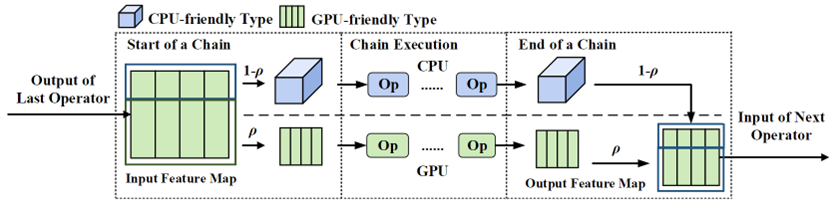
在离线阶段,CoDL设计了一个轻量的高效时延预测器用于指导在现阶段的算子切分。在线阶段包含算子分割器和算子协同执行器两个模块,算子分割器用于找出最优算子分割方案,其使用多维数据分割和算子链两种技术得到最优方案。算子分割器首先通过多维数据分割找到每个算子的最优分割维度(H,OC)和分割比作为基础方案。基于分割方案,使用算子链技术将算子组成链状,使得连上的算子不需要共享数据。算子协同执行器基于分割方案在处理器上协同运行工作负载,并针对不同处理器使用处理器友好的数据类型。如图6,CoDL在CPU和GPU间共享数据,将GPU友好型数据转化为CPU友好型数据交给CPU处理,之后CPU和GPU并行执行一条算子链上的算子。最终,CPU的推理结果被转换回GPU友好型数据和GPU的推理结果合并。
3.1多友好型数据共享
3.1.1多维数据分割
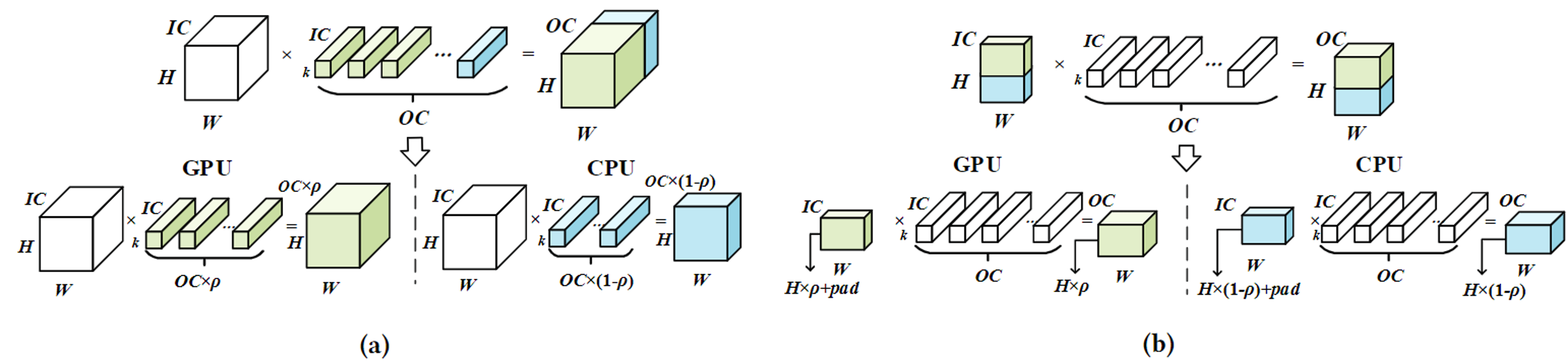
在张量的不同维度上进行分割会产生不同的性能影响,图7展示了在OC和H维度上进行张量分割的情况。虽然在H维度上进行分割可以减小数据共享量(模型权重是固定不变的,可以预分配),但相较于OC维度上的分割,在H和W较小时可能会导致较低的处理器利用率(图8)。因此,分割的维度应该由每个算子的形状决定。CoDL的多维数据分割基于提出的时延预测器,可以通过给定的输入算子设置、分割方案预测并行执行的总时延。基于预测的时延找到DL模型每个算子的最优分割维度和分割比。CoDL针对每个算子预测不同分割方案的总时延,预测时延最小的方案的分割维度将被选择。
3.1.2算子链
为了减少数据同步的次数,该文提出算子链技术,如图9,数据只需要在链上的开始和结束的算子上进行同步,其余算子只需使用本地数据。
虽然算子链可以有效减小数据同步的开销,但算子链越长需要padding的数据尺寸越大,将会造成更大的计算量,如图10所示,当算子链过长时,总时延可能反而会增大。
为了寻找能够最好地平衡数据同步和计算开销的算子链,该文提出了一个greedy-like算法。
3.2 非线性并行执行时延预测
数据分割和算子链技术都依赖于算子协同执行的时延预测,然而现有系统无法实现准确且轻量的时延预测,主要由于
1)没有考虑数据共享的开销;
2)由于忽视了应用平台的知识,预测器无法既准确又轻量。
本文准确且轻量的时延预测器通过以下方法实现。
1)引入所有数据共享的开销,;
2)通过分析性地对由平台特征引起的非线性延迟响应建模,降低学习的难度。基于对非线性延迟响应的分析,该文建立了如下时延预测的模型
由于非线性已经被提取,只需使用轻量的线性回归模型学习给定处理器执行一个基本单元的时延即可。
4. Comments
本文提出了一个在移动设备的CPU和GPU上协同执行模型推理的系统架构和方法,许多方法的提出基于作者对大量实验现象的观察。通过联系实验现象和系统基本特性,该文实现了针对于移动设备的准确且轻量的时延预测。同时,该文数据分割和算子链的设计也具有启发意义。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.