

1. 深层神经网络
深层神经网络与之前的浅层神经网络的不同之处在于网络的层数更多,或者说隐藏层的层数更多,网络更深,深度学习也是基于此命名的。在过去的几年中,DLI(Deep Learning Institute)已经意识到有一些函数,只有非常深的神经网络能学会,而更浅的模型则办不到,因此深度神经网络是十分重要的。但网络的深是深在网络层数上,而不在网络节点的数量多。
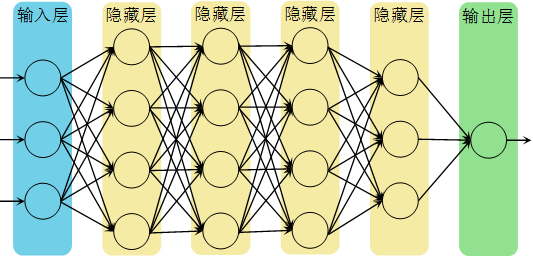
图1是一个深层神经网络的模型,它有5层,输入层算作第0层。本文用表示层数,该模型的,用表示每层的节点数,这里。
1.1 Forward Propagation (正向传播)
正向传播和浅层神经网络差别不大,也比较简单,只需不断向前迭代即可,可用(1)、(2)式表示。

当对多个样本进行训练时,可使用(3)、(4)式的向量形式。

该过程需要提供给系统进行初始化。
1.2Backward Propagation (反向传播)
反向传播通过对总代价求导得到的计算和 ,依次向前传递,计算出各和,便于运用梯度下降法对参数进行优化。反向传播可由(5)-(8)式进行计算。

向量化形式可写成(9)-(12)式。
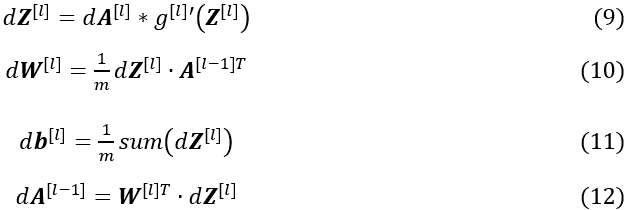
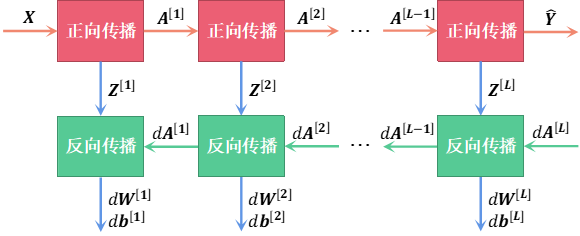
对整个正向传播和反向传播的过程进行总结可得到图2,其中系统将正向传播得到的进行缓存,并传递给反向传播各模块进行计算。
在计算过程中,确保各参数的维数正确是避免bug产生的重要手段,故将各参数的维数总结到表1中。

1.3 深层神经网络计算过程

当运行人脸识别程序时,输入给程序一张人脸照片,如图3所示,第一层神经网络可以看做在识别图像的边缘,每个节点负责不同方向的边缘,如第一张图所示。识别到边缘后交给第二层网络进行计算,它将各个边缘组合起来变成人体的各个部位,每个结点负责不同的部位,如第二张图所示,后面层的结点可能会将各部位再进行组合变成一张人脸,对此进行识别,这就是深度神经网络在进行计算时所经历的大致过程。总的来说,这是一个由小的区域到大的区域,由简单到复杂的过程。
1.4 编程实现深层神经网络
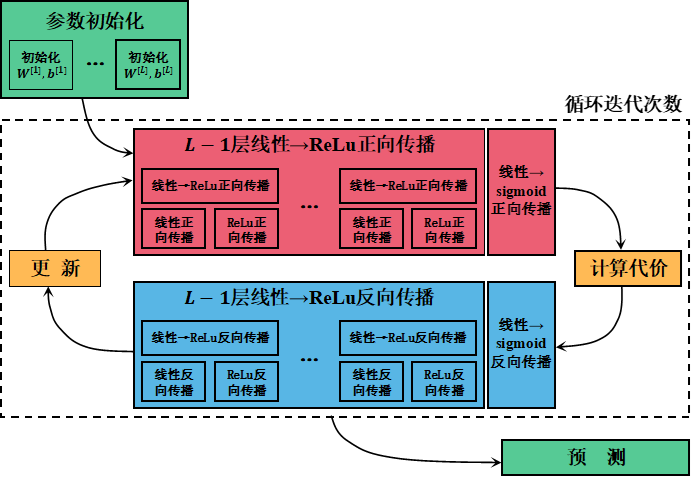
由上面几节已经知道了深层神经网络中的几种重要计算,现将训练整个深层神经网络的过程归纳为图4所示的流程,并由此编程搭建深层神经网络。本文设计了一个4层深层神经网络作为编程对象,第0-4层分别有12288、20、7、5和1个节点。
程序用到的函数及功能说明如表2所示。
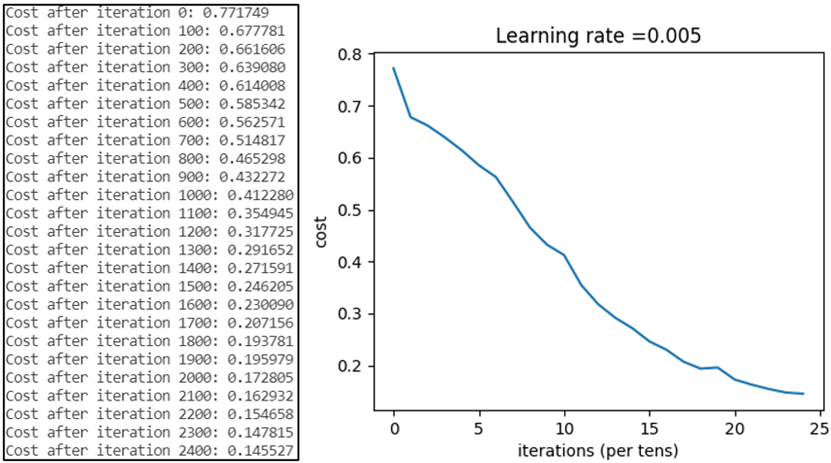
现采用与浅层神经网络相同的训练集进行模型训练,迭代次数为3000次,仅为浅层神经网络程序的十分之三,学习率同为0.005。总代价随着迭代次数的变化如图5所示,可以发现相同迭代次数下,深层神经网络的总代价略高于浅层神经网络。
2. 深层神经网络与浅层神经网络比较
对浅层神经网络进行测试发现,只可识别正面较标准的猫图片,对于角度较偏或姿势奇特的图片不可识别。现采用深层神经网络对这些难以识别的图片进行对比测试,得到的测试结果如表3所示。

从上表可以看出,尽管深层神经网络迭代次数仅为浅层神经网络的四分之一,深层神经网络比浅层神经网络识别正确率高得多。并且可以发现,对于这些猫图片,深层神经网络预测的概率几乎全部为1或近似于1,比浅层神经网络概率高很多,可见其性能的优异。
3. 总结
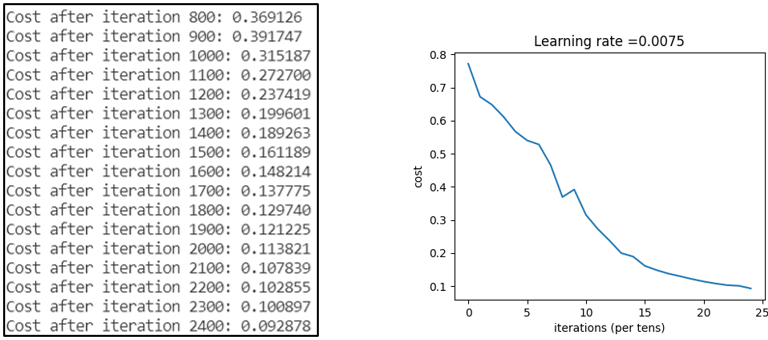
从测试结果中看,神经网络凭借较少的训练次数就可拥有远超浅层神经网络的性能,这是十分令人兴奋的。同时,深层神经网络模型对表3中的第4张图片预测错误,这时,将学习率从0.005改为0.0075,再次对模型进行训练,得到的总代价如图6所示,比学习率为0.005时小。再次对该图片进行预测得到了如图7所示的结果,预测正确,且概率达到了1。这说明学习率的选择对模型的性能有很大影响,这也引起了我们对超参数优化的兴趣,关于模型优化方面的内容将在后续文章中阐述。

- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.