

1.引言
深层学习在应用于大量数据时需要花费大量的训练时间,这成为了阻碍深度学习发展的一个困难。本文总结了几种可以加速深度学习模型训练过程的优化算法,采用Mini-batch优化算法可以有效缓解迭代缓慢的问题,在部分数据处理的过程中持续更新参数;Momentum算法、RMSprop算法和Adam算法能够加速梯度的下降过程,减小梯度在不必要方向上的抖动。
2. Mini-batch梯度下降法
之前我们在反向传播中所用的梯度下降算法,称为batch梯度下降法,在每次计算完毕所有样本对应的和后,再将和的值进行更新。这对于数据量小的数据集没有问题,应用向量化的方式也可以很快地进行迭代,但当数据量巨大时,对每个矩阵的处理时间同样是巨大的,这意味着经过很长一段时间才能进行一次梯度下降,这会严重影响模型训练的速度。
Mini-batch的方法将很大的数据集分解为多个子训练集,如图1所示,将原来的大数据集随机打乱排序,再划分为具有相同数据量的子集,以保证数据的均匀性,本文将第t个子集表示为,对应的标签为。
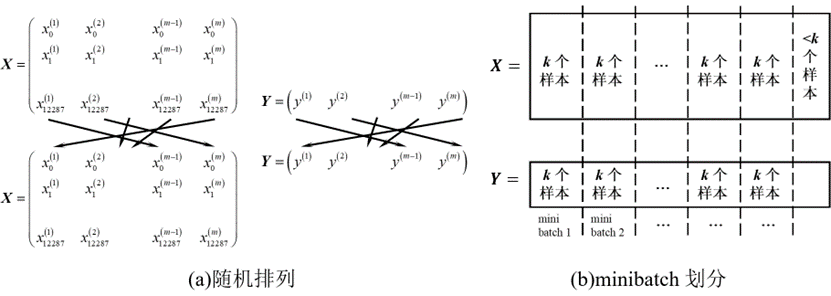
Mini-batch方法对每个子集逐一进行梯度下降,每将所有子集遍历一次称为一代(epoch),与原来的batch方法相比,mini-batch梯度下降法的梯度下降更新参数次数提高了子集数倍数,梯度下降算法也能更快执行。
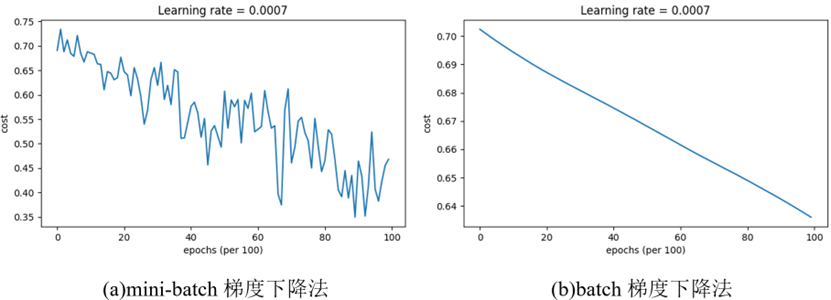
Mini-batch梯度下降法的代价函数随迭代次数的变化与batch法是不同的,图2为某测试数据集,分别对其使用mini-batch和batch梯度下降,得到的总代价曲线如图3所示(本文中的程序均使用3层模型,1到3层的节点数分别为5、2、1)。可以看到,mini-batch梯度下降法在梯度下降的过程中存在很多类似噪声的起伏,但总体趋势还是下降的;batch梯度下降法的总代价函数在学习率适中的情况下可以单调下降。经过相同的迭代次数,mini-batch梯度下降算法得到的总代价更小,说明与batch梯度下降法相比,mini-batch在未完整遍历整个训练集时就开始不断梯度下降更新参数,具有更快的训练速度。
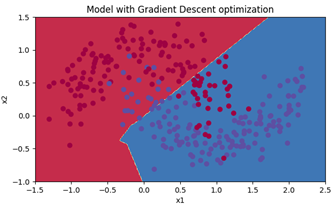
对Mini-batch梯度下降法得到的模型采用不同的颜色进行分割得到图4,对训练集的准确率如图5所示,为79.67%。

上文中出现的总代价抖动的情况是由于每次训练的数据子集不同,会存在某些数据子集将模型的训练偏离总代价小的方向,而batch梯度下降法每次训练的数据集相同,总代价不会向着增大的方向移动,但mini-batch梯度下降法能更持续地靠近最小值的方向,使用三维图形表示如图7所示。因此,mini-batch梯度下降法不会使最终代价收敛到某一点上,而是在最优点附近。
Mini-batch梯度下降法的优点是能更持续地优化模型,但每个子集分割得越小,向量化带来的速度增益就消失得越严重。当每个子集为1个数据时,就完全失去了向量化的加速。因此,合理地选择mini-batch子集的大小是十分重要的。
3. Momentum梯度下降法
3.1 指数加权平均
指数加权平均在统计中也叫指数加权移动平均,可以用于对数据进行平滑,可总结为方程

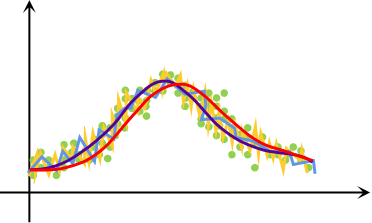
其中,为t时刻指数加权平均后的值,为时刻的原始数据,为权重系数,越小,平均的数据范围越大。图8为用指数加权平均进行平滑的示意图,各曲线按从小到大排序为黄、蓝、紫、红,当权重较小时,只对小范围数据进行了平滑,所以数据抖动明显,当权重较大时,红色曲线与理想曲线有一定的偏移,这是由于平滑了过多的数据。因此,合理选择权重可以做到对抖动数据的有效平滑,而权重过小会导致数据的偏移。
3.2 指数加权平均的偏差修正
在指数加权的初始阶段,被设置为0。经过第一次运算后,仅为的倍,这会比真实值相差很多,因为一般会取得很大。为了修正这个偏差,可以将修改为,当t很小时,可以有效弥补指数加权的偏差。而当很大时, 就接近于1,基本不会产生效果,这使得修正后的值与真实值很相近。当然,如果不关注初始训练时的偏差,也可以不做任何处理,等过了初始阶段就会有比较准确的数据。
3.3 Momentum梯度下降法
Momentum梯度下降法可以加速学习的过程,其思想为:对梯度进行指数加权平均,并利用指数加权平均后的梯度更新权重。算法流程如下:

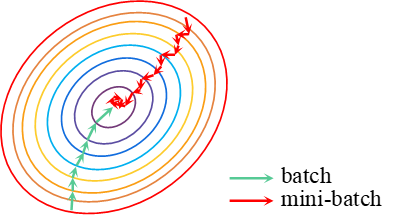
假设有一代价函数如图9所示,由于是一椭圆状,绿色箭头表示的梯度下降过程呈抖动下降的趋势。这种情况下的梯度下降只能采用较小的学习率,如果学习率过大会使结果偏离函数的范围,这会导致学习速度缓慢。

当对梯度进行指数加权平均后,纵轴上的方向相反的梯度相互抵消使得平均值很小,而指向最优点的横轴方向由于梯度方向一致,仍会有一个较大的平均值。因此,该情况下可以使用较大的学习率进行梯度下降,加速了学习的过程。另外,人们经常将 的值设置为0.9,实践表明该数值具有很好的鲁棒性。
3.4 编程实现Momentum梯度下降
采用Momentum算法对相同数据集采用mini-batch的方法进行训练,得到的模型用颜色进行分割如图10所示,对训练集的准确度如图11所示,为79.67%。
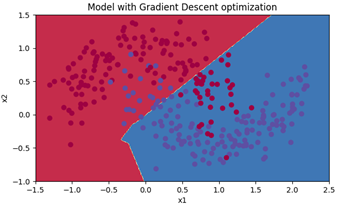

这和单纯用mini-batch梯度下降法进行计算得到的结果相同,原因在于该模型过于简单,momentum梯度下降法在训练过程中没有起到过多作用,但当模型很复杂时,就可以看出差别。
4.RMSprop算法
RMSprop算法的全称是Root Mean Square Prop,意为采用均方根的方式加快学习进程。其算法流程如下:
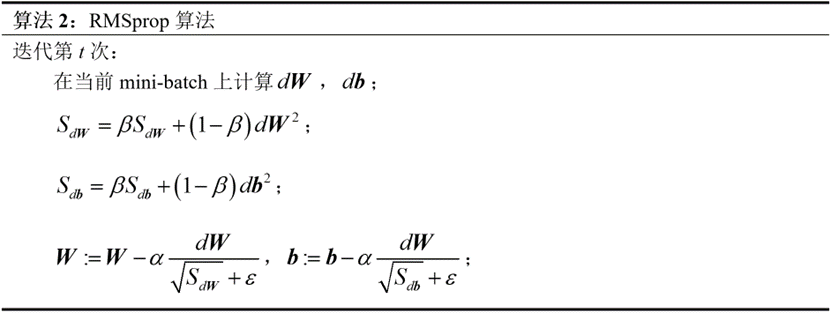
该算法仍可采用上节的例子进行理解,分别对的平方进行指数加权平均。当某一维度存在震荡时,其导数会很大,计算得到的值也会很大,使得对该维度的更新更慢;当指向最低代价的维度出现梯度下降慢的情况时,其导数会较小,相应的值也会更小,该维度更新得就会加快,缓解了学习的瓶颈。该算法中的值推荐使用0.999,算法中用到的主要是为了防止0成为分母导致程序出错,一般使用即可。
5. Adam优化算法
Adam算法可以简单理解为是将Momentum算法和RMSprop算法结合起来的优化算法,其算法流程如下:

可以看到,Adam算法既对和进行了指数加权平均以减轻抖动,又对他们进行了均方根的运算以缓解梯度下降过程中的瓶颈。另外,运用Adam算法时一般会进行偏差修正,所以对 都进行了的偏差修正。这里,根据Momentum梯度下降算法和RMSprop算法的内容对不同的进行了角标区分,取0.9,取0.999,取。
仍采用上面章节中使用的模型和数据集,得到的总代价随代数变化的曲线如图12所示,对训练得到的模型按照颜色进行划分如图13所示,该模型对训练集的准确度如图14所示。
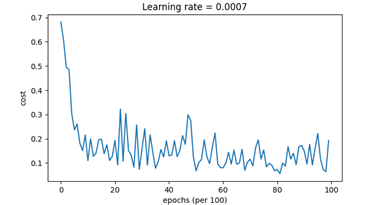
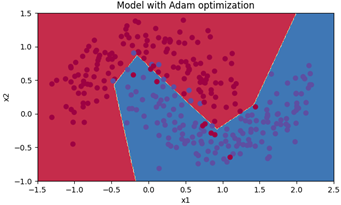
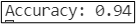
可以发现,与单纯使用mini-batch算法和叠加momentum算法的模型相比,相同的迭代次数下,Adam算法很快就到达了很小的代价,其精确度也提高了许多,说明Adam确实能在很大程度上提高训练的速度。
6. 学习率衰减
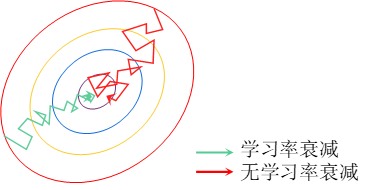
在前面应用mini-batch进行模型训练的过程中,由于数据子集的不统一性,会产生许多噪声,导致总代价无法收敛到最优点而在附近徘徊。学习率衰减指将学习率随着迭代的次数不断减小,该情况下会使梯度下降的步伐不断减少,从而使得总代价最终十分接近最优点。对学习率衰减形象地用图形表示如图15所示。
对于学习率衰减,有几种常用的方法:一种是采用下式进行学习率衰减

其中,为初始学习率,为衰减率,为代数。
也可以使用如下称为指数学习率衰减的公式

还有一些公式,如等,都具有一定的效果,甚至还可以在模型训练的过程中手动调节学习率。虽然学习率衰减确实有时能加快训练,但学习率衰减通常不是考虑的第一位,选择一个合适的超参数往往会更有用。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.