

1.逻辑回归
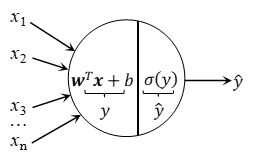
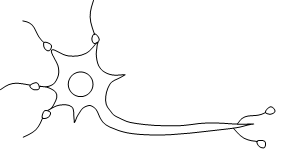
逻辑回归可以理解为不具备hidden layer(隐藏层)的神经网络,其模型如图1所示。逻辑回归能通过线性计算预测输入特征值对应的输出,其中的特征权重w和偏差b决定着预测的准确度,因此获得合适的w和b是此模型的重点。使用输入加权的原因可以从人的神经元中找到答案,图2是人的神经元模型,可能同时有多个电信号作用于神经元,当它们的加权和大于神经元的阈值时,其就会在轴突产生输出电信号,神经网络就是由此发展而来的。
1.1 梯度下降法逻辑回归
利用给定的一组带标记的训练集进行代数运算获取w和b是一项艰巨的工作,甚至是难以完成的,人工智能的发展也因此一度停滞不前。梯度下降法的提出解决了这一问题,虽然其获得的可能不是最优解,但至少让这一过程有解。梯度下降法的思路是:初始随机选择参数,根据预测值与期望值的偏差反向传播误差,进而调整参数的大小。就像从山的任意位置沿着梯度的方向朝着谷底前进,谷底就是预测偏差最小的位置,也就是模型训练的目标点。表1列出了本文会用到的符号解释。

当输入值多于一个时,需要程序循环多次以计算对应的预测值,但在编程时,大量使用for循环会极大影响程序执行速度。为了解决这个问题,我们尽量采用向量的形式表示各个值,应用python内嵌函数可以轻松地处理向量的运算,经过比较,向量形式比for循环形式快数百倍。因此,本文均采用向量形式进行计算。
逻辑回归的过程可以分为forward propagation (向前传播)和backward propagation(向后传播)两个过程。向前传播通过上面所述的过程计算当前参数对应预测值的代价(或损失),向后传播采用链式法则计算总代价(或总损失)对各参数的偏导数,根据设定的学习率更新参数。之后重复前述操作,直到达到理想的代价或者迭代次数为止。
具体的逻辑回归模型训练过程如下:

1.2 编程实现逻辑回归
现通过python编程搭建逻辑回归模型实现“猫识别”,程序采用模块化方式编写,用到的函数如表2所示。本文采用可下载的h5文件数据集进行模型训练,也可采用CSV文件数据集。

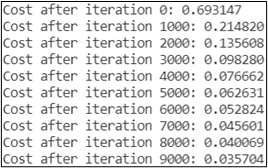
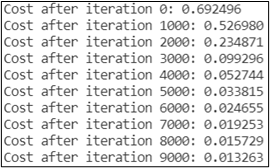
本文模型训练迭代10000次,学习率采用0.005。运行程序,可以看到总代价随着训练次数逐渐减小,如图3所示。
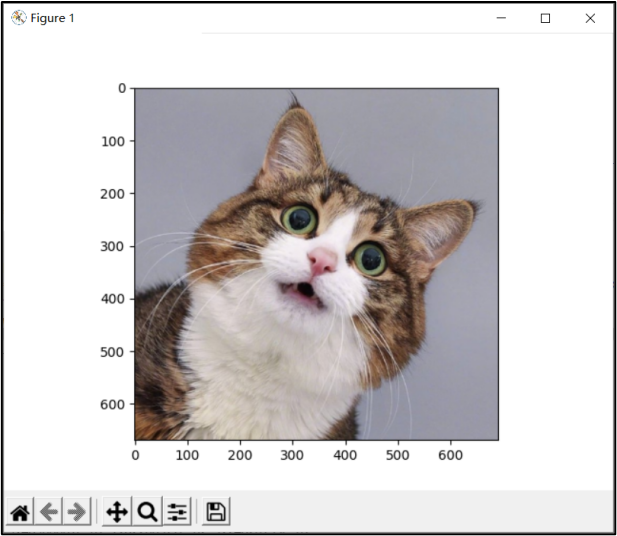
下面随意下载一张猫的图片交给程序进行预测,图4为交给程序的猫图片,程序对图片预测后输出该图片是猫的概率,若概率大于0.5则判定该图片有猫,并显示预测结果,如图5所示。可以看到,程序预测该图片有99.66%的概率为猫。

为了测试程序不会把所有图片认定为猫,再对一不含猫的图片进行预测,如图6所示。预测结果如图6所示,程序预测该图片有33.74%的概率为猫,认为这不是一张含有猫的图片。可以看出,程序可以正确分辨有无猫在图片中。

经过多次测试,发现程序对正面较清晰的猫识别概率很高,有些情况下存在识别错误。另外,对于一些与猫相近的狗的正面照也存在识别为猫的情况。
2.浅层神经网络
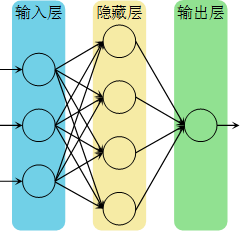
逻辑回归可以看为只有一层的神经网络,也可以理解为人脑的一个神经元,将多个逻辑回归中的单元叠起来就变成了神经网络,如图8所示。其中,输入层也称为第0层,因此下图的神经网络被称为2层神经网络。
2.1 神经网络的表示
神经网络的节点数比逻辑回归多,需要对逻辑回归的向量形式做一定的调整。本文采用上标 [1]表示第1层神经网络,第0层的X可用
表示,w从之前的1维向量变为矩阵W,其中,为方便后续计算,已将对应的w进行转置,如(5)式所示。

每层的输出可通过(6)式计算

其中,相当于第0层的输入,即X。下面以第1层为例推导该过程的维度对应关系:
2.1.1 forward propagation(正向传播)
只有2层的浅层神经网络的正向传播可由以下4个式子求得

2.1.2 backward propagation(反向传播)
反向传播可总结为以下6个公式 (输出层采用sigmoid函数作为激活函数)
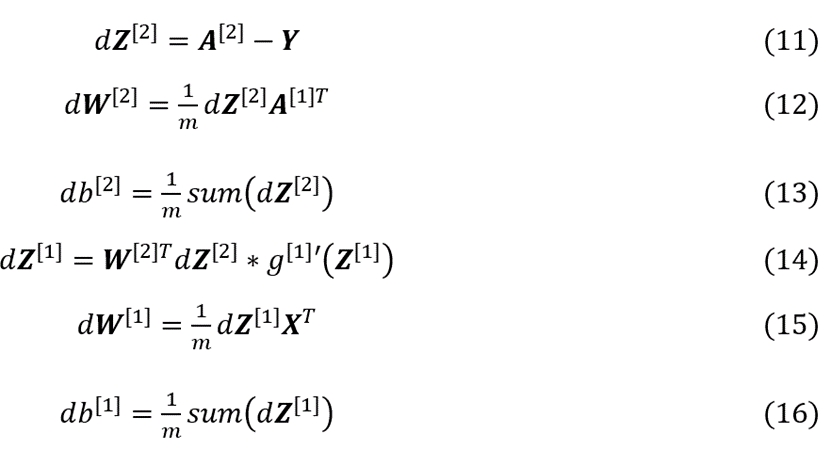
其中,(11)、(12)、(13)、(15)和(16)式原理同(2)-(4)式,现对(14)式进行适当推导。运用链式法则,可得
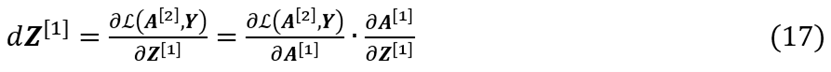
其中,
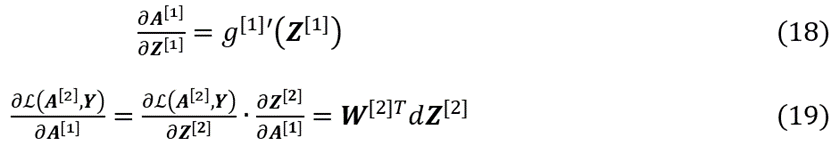
综合(17)-(19)式以上各式可得
2.1.3 浅层神经网络训练过程
具体的浅层神经网络训练过程如下(以2层为例):
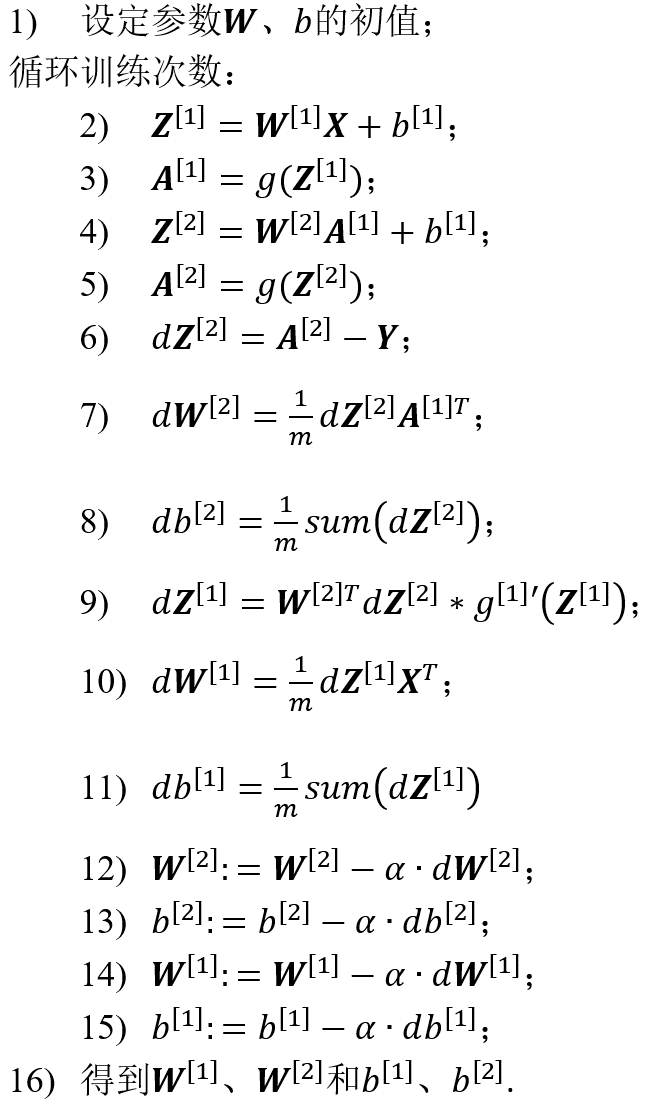
2.1.4 激活函数的选择
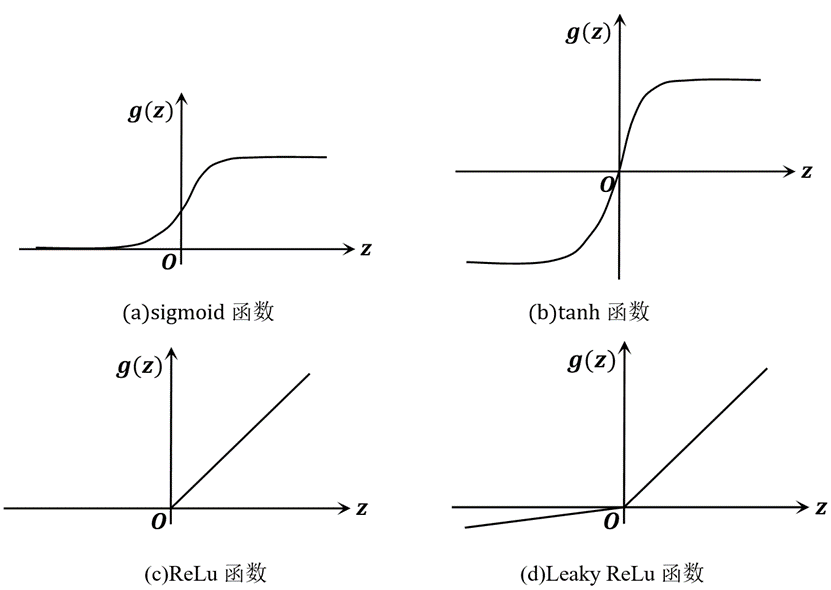
神经网络需要非线性的激活函数,因为如果激活函数是线性的,那么无论有多少隐藏层,都可以看作是一组线性组合,那么都会浓缩为1层,这显然是毫无意义的。在逻辑回归中用到的是sigmoid函数,如图9(a)所示,然而另外一种非线性函数tanh在大多数情况是更受欢迎的,如图9(b)所示,它覆盖了-1到1的值域,这在神经网络中会取得更好的效果,但如果模型所解决的是一个二分类问题,期望得到的是0或1,可以考虑在输出层使用sigmoid函数。这两个函数都存在一个问题,当z太大或太小时斜率接近于0,这会导致学习饱和,所以可以采用ReLu函数或Leaky ReLu函数代替,如图9(c)、(d)所示,他们都可以保证z较大时不错的收敛速度。
前述计算过程中,激活函数的导数经常被用到,因此本文将几种激活函数的导数整理到表3中。

2.1.5 随机初始化
训练神经网络时,权重随机初始化是十分重要的。当把权重W全部初始化为0时,同层的隐藏单元计算着同一个函数,他们对输出的影响也全部相同,无论经过多少次迭代他们都计算着相同的函数。也就是说,这和只有一个隐藏单元没有任何差别。为了解决这一问题,我们应当将W随机初始化,而b没有这个问题,可以将其初始化为0。
2.2 编程实现浅层神经网络
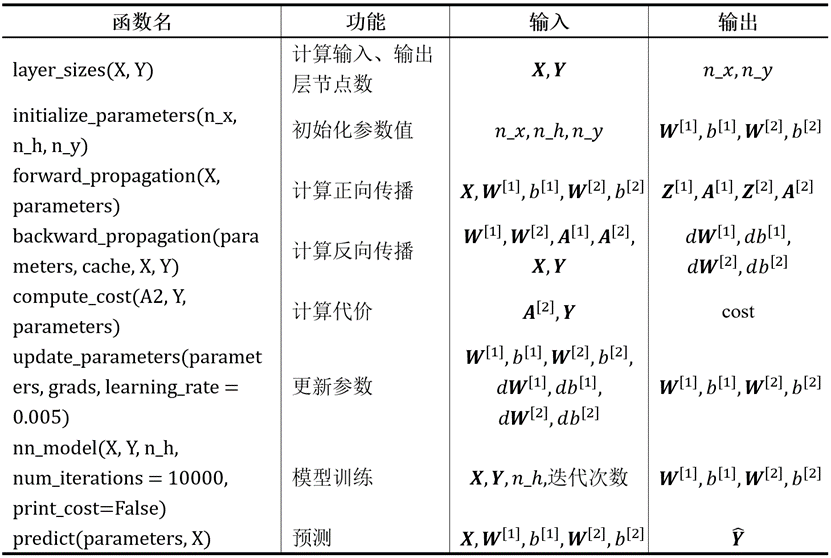
现编程搭建只有一个隐藏层的浅层神经网络,隐藏层设置5个节点,用到的函数如表4所示。
为了方便比较,本文采用与逻辑回归程序相同的数据集进行训练,迭代次数同为10000次,总代价的变化如图10所示。可以发现,相同的迭代次数下,浅层神经网络比逻辑回归单节点网络的代价0.035704要小。
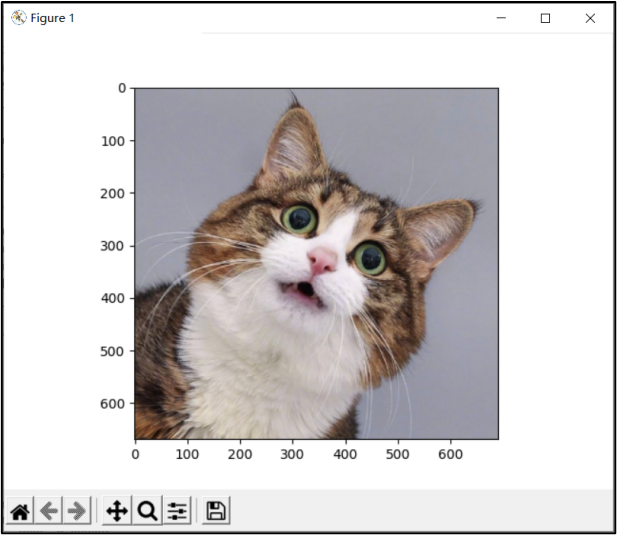

现使用与逻辑回归程序相同的两张图片对浅层神经网络进行测试。如图11所示,程序预测该图片有99.51%的概率为猫图片,相比逻辑回归单节点99.66%的概率略有降低,但两种情况下预测的概率都接近100%,可以认为识别效果都十分不错,并不能看出优劣。为了更加清晰地比较两种模型,我们选取一张不太标准的猫图片进行识别,如图13所示。
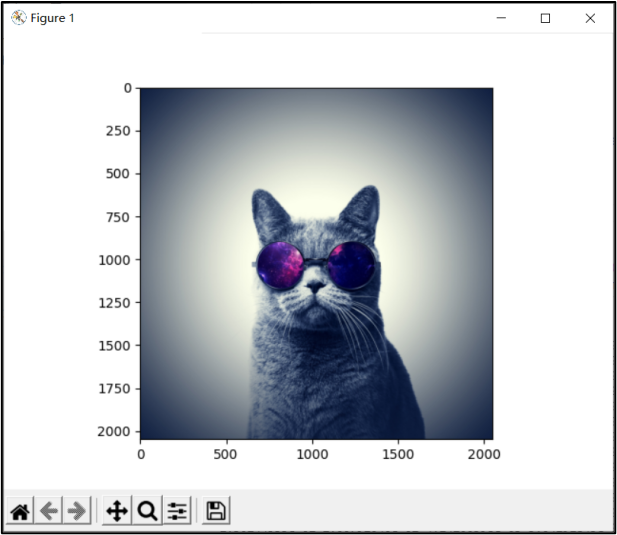
逻辑回归的单节点模型预测的结果如图14所示,浅层神经网络预测的结果如图15所示。


可以看到,浅层神经网络的预测结果比单节点模型概率高8.86%,浅层神经网络的预测能力更强。
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.